- January 21, 2018
- Vasilis Vryniotis
- . 1 Remark
 Deep Studying (the favorite buzzword of late 2010s together with blockchain/bitcoin and Information Science/Machine Studying) has enabled us to do some actually cool stuff the previous few years. Aside from the advances in algorithms (which admittedly are primarily based on concepts already identified since Nineties aka “Information Mining period”), the principle causes of its success could be attributed to the supply of enormous free datasets, the introduction of open-source libraries and the usage of GPUs. On this weblog submit I’ll deal with the final two and I’ll share with you some suggestions that I realized the exhausting method.
Deep Studying (the favorite buzzword of late 2010s together with blockchain/bitcoin and Information Science/Machine Studying) has enabled us to do some actually cool stuff the previous few years. Aside from the advances in algorithms (which admittedly are primarily based on concepts already identified since Nineties aka “Information Mining period”), the principle causes of its success could be attributed to the supply of enormous free datasets, the introduction of open-source libraries and the usage of GPUs. On this weblog submit I’ll deal with the final two and I’ll share with you some suggestions that I realized the exhausting method.
Why TensorFlow & Keras?
TensorFlow is a very talked-about Deep Studying library developed by Google which lets you prototype rapidly advanced networks. It comes with a number of fascinating options akin to auto-differentiation (which saves you from estimating/coding the gradients of the associated fee features) and GPU assist (which lets you get simply a 200x velocity enchancment utilizing first rate {hardware}). Furthermore it presents a Python interface which suggests which you could prototype rapidly with out requiring to write down C or CUDA code. Admittedly there are many different frameworks one can use as an alternative of TensorFlow, akin to Torch, MXNet, Theano, Caffe, Deeplearning4j, CNTK, and so forth but it surely all boils all the way down to your use-case and your private choice.
However why Keras? For me utilizing straight TF is like doing Machine Studying with Numpy. Sure it’s possible and every so often it’s a must to do it (particularly in case you write customized layers/loss-functions) however do you actually need to write code that describes the advanced networks as a collection of vector operations (sure, I do know there are higher-level strategies in TF however they don’t seem to be as cool as Keras)? Additionally what if you wish to transfer to a unique library? Effectively then you definately would in all probability have to rewrite the code, which sucks. Ta ta taaa, Keras to the rescue! Keras means that you can describe your networks utilizing excessive degree ideas and write code that’s backend agnostic, which means which you could run the networks throughout totally different deep studying libraries. Few issues I really like about Keras is that it’s well-written, it has an object oriented structure, it’s simple to contribute and it has a pleasant neighborhood. If you happen to prefer it, say thanks to François Chollet for creating it and open-sourcing it.
Suggestions and Gotchas for Multi-GPU coaching
With out additional ado, let’s soar to a couple recommendations on the right way to benefit from GPU coaching on Keras and a few gotchas that you need to take into account:
1. Multi-GPU coaching is just not computerized
Coaching fashions on GPU utilizing Keras & Tensorflow is seamless. If in case you have an NVIDIA card and you’ve got put in CUDA, the libraries will routinely detect it and use it for coaching. So cool! However what in case you are a spoilt brat and you’ve got a number of GPUs? Effectively sadly you’ll have to work a bit to realize multi-GPU coaching.![]()
There are a number of methods to parallelise a community relying on what you need to obtain however the principle two approaches is mannequin and knowledge parallelization. The primary may help you in case your mannequin is simply too advanced to slot in a single GPU whereas the latter helps once you need to velocity up the execution. Usually when individuals discuss multi-GPU coaching they imply the latter. It was once tougher to realize however fortunately Keras has just lately included a utility technique known as mutli_gpu_model which makes the parallel coaching/predictions simpler (presently solely obtainable with TF backend). The primary thought is that you just go your mannequin by means of the strategy and it’s copied throughout totally different GPUs. The unique enter is cut up into chunks that are fed to the assorted GPUs after which they’re aggregated as a single output. This technique can be utilized for reaching parallel coaching and predictions, however needless to say for coaching it doesn’t scale linearly with the quantity of GPUs because of the required synchronization.
2. Take note of the Batch Measurement
Once you do multi-GPU coaching take note of the batch measurement because it has a number of results on velocity/reminiscence, convergence of your mannequin and in case you are not cautious you would possibly corrupt your mannequin weights!
Velocity/reminiscence: Clearly the bigger the batch the quicker the coaching/prediction. It is because there’s an overhead on placing in and taking out knowledge from the GPUs, so small batches have extra overhead. On the flip-side, the bigger the batch the extra reminiscence you want within the GPU. Particularly throughout coaching, the inputs of every layer are stored in reminiscence as they’re required on the back-propagation step, so growing your batch measurement an excessive amount of can result in out-of-memory errors.
Convergence: If you happen to use Stochastic Gradient Respectable (SGD) or a few of its variants to coach your mannequin, you need to take into account that the batch measurement can have an effect on the power of your community to converge and generalize. Typical batch sizes in lots of laptop imaginative and prescient issues are between 32-512 examples. As Keskar et al put it, “It has been noticed in apply that when utilizing a bigger batch (than 512) there’s a degradation within the high quality of the mannequin, as measured by its potential to generalize.”. Be aware that different totally different optimizers have totally different properties and specialised distributed optimization strategies may help with the issue. If you’re within the mathematical particulars, I like to recommend studying Joeri Hermans’ Thesis “On Scalable Deep Studying and Parallelizing Gradient Descent”.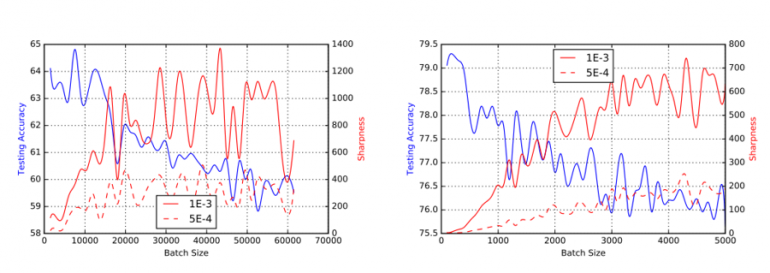
Corrupting the weights: It is a nasty technical element which might have devastating outcomes. Once you do multi-GPU coaching, you will need to feed all of the GPUs with knowledge. It will probably occur that the final batch of your epoch has much less knowledge than outlined (as a result of the scale of your dataset cannot be divided precisely by the scale of your batch). This would possibly trigger some GPUs to not obtain any knowledge over the last step. Sadly some Keras Layers, most notably the Batch Normalization Layer, can’t deal with that resulting in nan values showing within the weights (the operating imply and variance within the BN layer). To make the issues even nastier, one is not going to observe the issue throughout coaching (whereas studying part is 1) as a result of the precise layer makes use of the batch’s imply/variance within the estimations. However throughout predictions (studying part set to 0), the operating imply/variance is used which in our case can turn into nan resulting in poor outcomes. So do your self a favour and all the time ensure that your batch measurement is mounted once you do multi-GPU coaching. Two easy methods to realize that is both by rejecting batches that don’t match the predefined measurement or repeat the data inside the batch till you attain the predefined measurement. Final however not least needless to say in a multi-GPU setup, the batch measurement must be a a number of of the variety of obtainable GPUs in your system.
3. GPU knowledge Hunger aka the CPUs can’t sustain with the GPUs
Usually the most costly half whereas coaching/predicting Deep networks is the estimation that occurs on the GPUs. The info are preprocessed within the CPUs on the background and they’re fed to the GPUs periodically. However one mustn’t underestimate how briskly the GPUs are; it might occur that in case your community is simply too shallow or the preprocessing step is simply too advanced that your CPUs can’t sustain together with your GPUs or in different phrases they don’t feed them with knowledge rapidly sufficient. This will result in low GPU utilization which interprets to wasted cash/assets.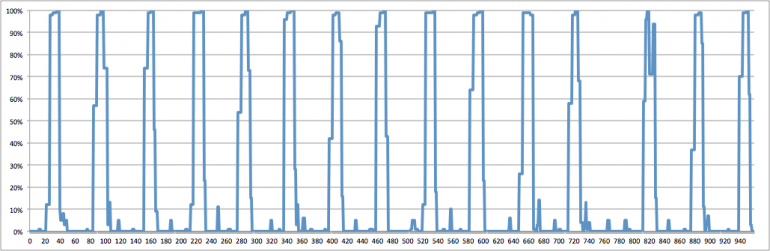
Keras sometimes performs the estimations of the batches in parallel however resulting from Python’s GIL (International Interpreter Lock) you may’t actually obtain true multi-threading in Python. There are two options for that: both use a number of processes (word that there are many gotchas on this one which I’m not going to cowl right here) or maintain your preprocessing step easy. Previously I’ve despatched a Pull-Request on Keras to alleviate a number of the pointless pressure that we had been placing on the CPUs throughout Picture preprocessing, so most customers shouldn’t be affected in the event that they use the usual mills. If in case you have customized mills, attempt to push as a lot logic as attainable to C libraries akin to Numpy as a result of a few of these strategies truly launch the GIL which suggests which you could improve the diploma of parallelization. A great way to detect whether or not you might be dealing with GPU knowledge hunger is to watch the GPU utilization, however be warned that this isn’t the one motive for observing that (the synchronization that occurs throughout coaching throughout the a number of GPUs can be guilty for low utilization). Usually GPU knowledge hunger could be detected by observing GPU bursts adopted by lengthy pauses with no utilization. Previously I’ve open-sourced an extension for Dstat that may provide help to measure your GPU utilization, so take a look on the authentic weblog submit.
4. Saving your parallel fashions
Say you used the mutli_gpu_model technique to parallelize your mannequin, the coaching completed and now you need to persist its weights. The unhealthy information is which you could’t simply name save() on it. At present Keras has a limitation that doesn’t mean you can save a parallel mannequin. There are 2 methods round this: both name the save() on the reference of the unique mannequin (the weights will likely be up to date routinely) or you should serialize the mannequin by chopping-down the parallelized model and cleansing up all of the pointless connections. The primary choice is method simpler however on the long run I plan to open-source a serialize() technique that performs the latter.
5. Counting the obtainable GPUs has a nasty side-effect
Sadly in the intervening time, there’s a nasty side-effect on the tensorflow.python.shopper.device_lib.list_local_devices() technique which causes a brand new TensorFlow Session to be created and the initialization of all of the obtainable GPUs on the system. This will result in sudden outcomes akin to viewing extra GPUs than specified or prematurely initializing new classes (you may learn all the small print on this pull-request). To keep away from comparable surprises you might be suggested to make use of Keras’ Ok.get_session().list_devices() technique as an alternative, which is able to return you all of the presently registered GPUs on the session. Final however not least, needless to say calling the list_devices() technique is one way or the other costly, so in case you are simply on the variety of obtainable GPUs name the strategy as soon as and retailer their quantity on a neighborhood variable.
That’s it! Hope you discovered this checklist helpful. If you happen to discovered different gotchas/suggestions for GPU coaching on Keras, share them beneath on the feedback. 🙂
{kind=link}