Understanding the Limits of Present Interpretability Instruments in LLMs
AI fashions, akin to DeepSeek and GPT variants, depend on billions of parameters working collectively to deal with advanced reasoning duties. Regardless of their capabilities, one main problem is knowing which components of their reasoning have the best affect on the ultimate output. That is particularly essential for guaranteeing the reliability of AI in crucial areas, akin to healthcare or finance. Present interpretability instruments, akin to token-level significance or gradient-based strategies, supply solely a restricted view. These approaches usually give attention to remoted parts and fail to seize how totally different reasoning steps join and influence choices, leaving key facets of the mannequin’s logic hidden.
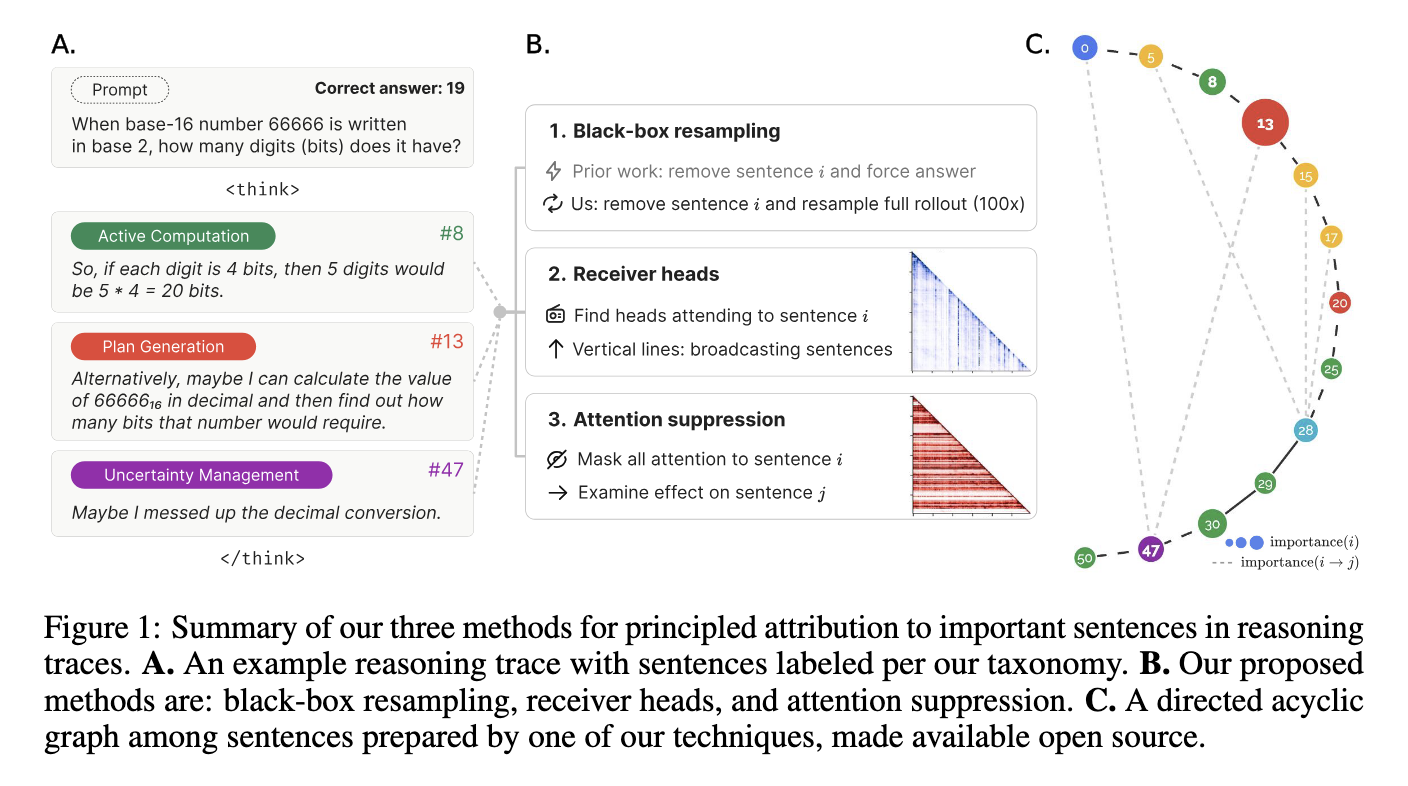
Thought Anchors: Sentence-Degree Interpretability for Reasoning Paths
Researchers from Duke College and Aiphabet launched a novel interpretability framework referred to as “Thought Anchors.” This technique particularly investigates sentence-level reasoning contributions inside giant language fashions. To facilitate widespread use, the researchers additionally developed an accessible, detailed open-source interface at thought-anchors.com, supporting visualization and comparative evaluation of inside mannequin reasoning. The framework includes three major interpretability parts: black-box measurement, white-box methodology with receiver head evaluation, and causal attribution. These approaches uniquely goal totally different facets of reasoning, offering complete protection of mannequin interpretability. Thought Anchors explicitly measure how every reasoning step impacts mannequin responses, thus delineating significant reasoning flows all through the inner processes of an LLM.
Analysis Methodology: Benchmarking on DeepSeek and the MATH Dataset
The analysis group detailed three interpretability strategies clearly of their analysis. The primary strategy, black-box measurement, employs counterfactual evaluation by systematically eradicating sentences inside reasoning traces and quantifying their influence. As an illustration, the examine demonstrated sentence-level accuracy assessments by working analyses over a considerable analysis dataset, encompassing 2,000 reasoning duties, every producing 19 responses. They utilized the DeepSeek Q&A mannequin, which options roughly 67 billion parameters, and examined it on a particularly designed MATH dataset comprising round 12,500 difficult mathematical issues. Second, receiver head evaluation measures consideration patterns between sentence pairs, revealing how earlier reasoning steps affect subsequent data processing. The examine discovered important directional consideration, indicating that sure anchor sentences considerably information subsequent reasoning steps. Third, the causal attribution methodology assesses how suppressing the affect of particular reasoning steps impacts subsequent outputs, thereby clarifying the exact contribution of inside reasoning parts. Mixed, these methods produced exact analytical outputs, uncovering specific relationships between reasoning parts.
Quantitative Beneficial properties: Excessive Accuracy and Clear Causal Linkages
Making use of Thought Anchors, the analysis group demonstrated notable enhancements in interpretability. Black-box evaluation achieved sturdy efficiency metrics: for every reasoning step throughout the analysis duties, the analysis group noticed clear variations in influence on mannequin accuracy. Particularly, right reasoning paths constantly achieved accuracy ranges above 90%, considerably outperforming incorrect paths. Receiver head evaluation supplied proof of sturdy directional relationships, measured by means of consideration distributions throughout all layers and a spotlight heads inside DeepSeek. These directional consideration patterns constantly guided subsequent reasoning, with receiver heads demonstrating correlation scores averaging round 0.59 throughout layers, confirming the interpretability methodology’s capability to successfully pinpoint influential reasoning steps. Furthermore, causal attribution experiments explicitly quantified how reasoning steps propagated their affect ahead. Evaluation revealed that causal influences exerted by preliminary reasoning sentences resulted in observable impacts on subsequent sentences, with a imply causal affect metric of roughly 0.34, additional solidifying the precision of Thought Anchors.
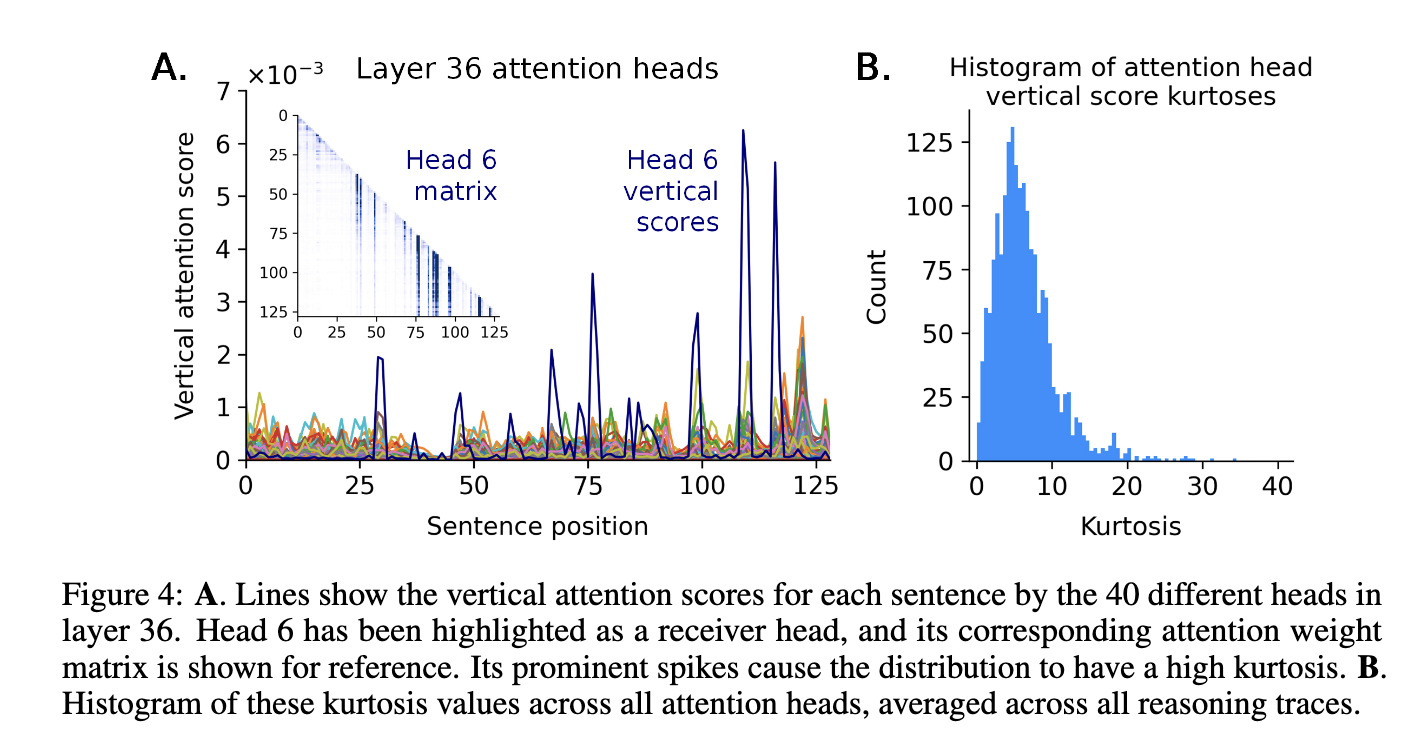
Additionally, the analysis addressed one other crucial dimension of interpretability: consideration aggregation. Particularly, the examine analyzed 250 distinct consideration heads throughout the DeepSeek mannequin throughout a number of reasoning duties. Amongst these heads, the analysis recognized that sure receiver heads constantly directed important consideration towards explicit reasoning steps, particularly throughout mathematically intensive queries. In distinction, different consideration heads exhibited extra distributed or ambiguous consideration patterns. The specific categorization of receiver heads by their interpretability supplied additional granularity in understanding the inner decision-making construction of LLMs, probably guiding future mannequin structure optimizations.
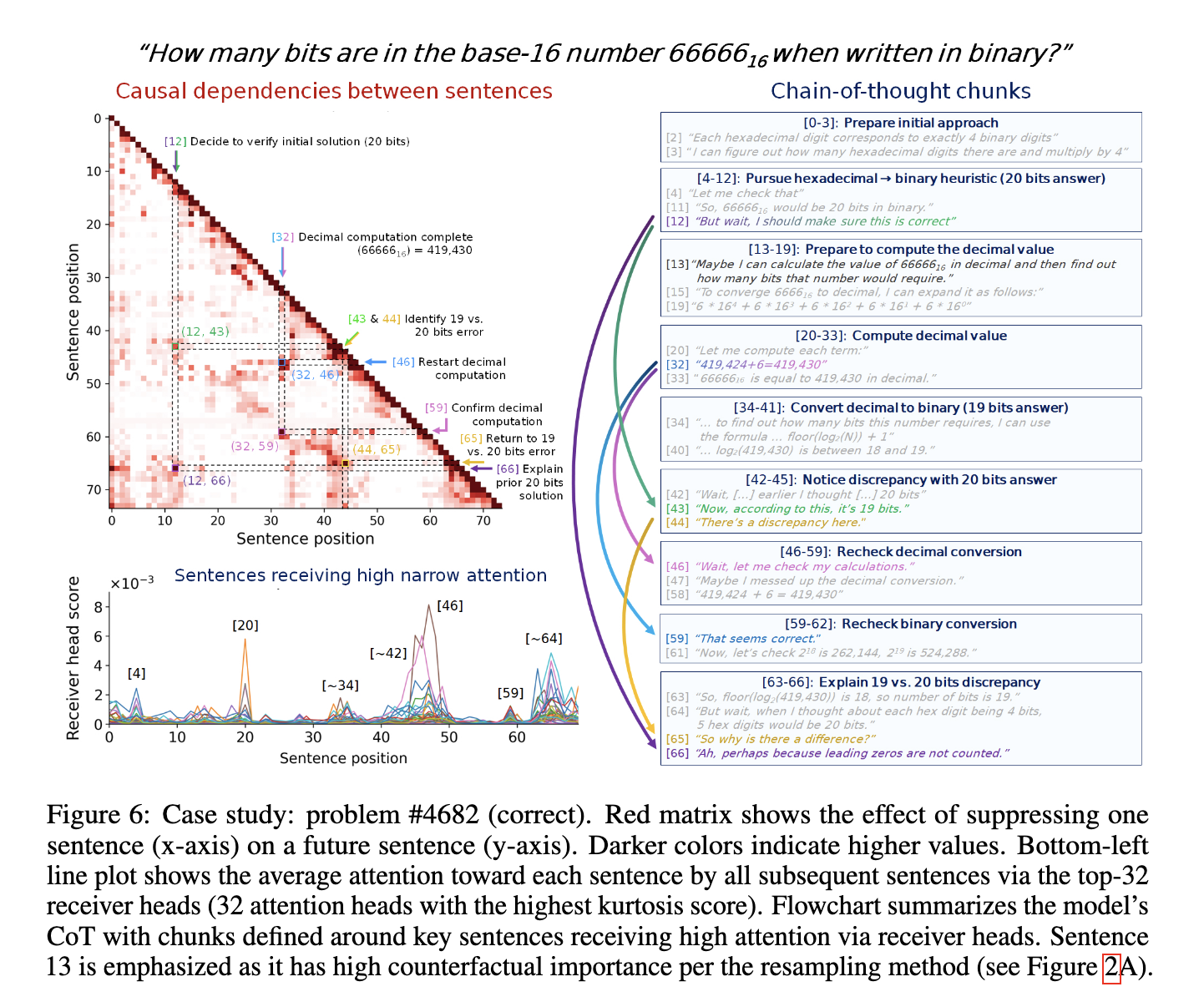
Key Takeaways: Precision Reasoning Evaluation and Sensible Advantages
- Thought Anchors improve interpretability by focusing particularly on inside reasoning processes on the sentence stage, considerably outperforming typical activation-based strategies.
- Combining black-box measurement, receiver head evaluation, and causal attribution, Thought Anchors ship complete and exact insights into mannequin behaviors and reasoning flows.
- The applying of the Thought Anchors methodology to the DeepSeek Q&A mannequin (with 67 billion parameters) yielded compelling empirical proof, characterised by a robust correlation (imply consideration rating of 0.59) and a causal affect (imply metric of 0.34).
- The open-source visualization device at thought-anchors.com offers important usability advantages, fostering collaborative exploration and enchancment of interpretability strategies.
- The examine’s intensive consideration head evaluation (250 heads) additional refined the understanding of how consideration mechanisms contribute to reasoning, providing potential avenues for enhancing future mannequin architectures.
- Thought Anchors’ demonstrated capabilities set up sturdy foundations for using refined language fashions safely in delicate, high-stakes domains akin to healthcare, finance, and important infrastructure.
- The framework proposes alternatives for future analysis in superior interpretability strategies, aiming to refine the transparency and robustness of AI additional.
Try the Paper and Interplay. All credit score for this analysis goes to the researchers of this venture. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.

{kind=link}