🚀 Able to supercharge your AI workflow? Strive ElevenLabs for AI voice and speech era!
Within the quickly evolving panorama of huge language fashions (LLMs), the highlight has largely centered on the decoder-only structure. Whereas these fashions have proven spectacular capabilities throughout a variety of era duties, the traditional encoder-decoder structure, comparable to T5 (The Textual content-to-Textual content Switch Transformer), stays a well-liked alternative for a lot of real-world purposes. Encoder-decoder fashions usually excel at summarization, translation, QA, and extra as a consequence of their excessive inference effectivity, design flexibility, and richer encoder illustration for understanding enter. However, the highly effective encoder-decoder structure has obtained little relative consideration.
Right this moment, we revisit this structure and introduce T5Gemma, a brand new assortment of encoder-decoder LLMs developed by changing pretrained decoder-only fashions into the encoder-decoder structure by way of a method known as adaptation. T5Gemma is predicated on the Gemma 2 framework, together with tailored Gemma 2 2B and 9B fashions in addition to a set of newly educated T5-sized fashions (Small, Base, Massive and XL). We’re excited to launch pretrained and instruction-tuned T5Gemma fashions to the group to unlock new alternatives for analysis and growth.
From decoder-only to encoder-decoder
In T5Gemma, we ask the next query: can we construct top-tier encoder-decoder fashions primarily based on pretrained decoder-only fashions? We reply this query by exploring a method known as mannequin adaptation. The core thought is to initialize the parameters of an encoder-decoder mannequin utilizing the weights of an already pretrained decoder-only mannequin, after which additional adapt them by way of UL2 or PrefixLM-based pre-training.
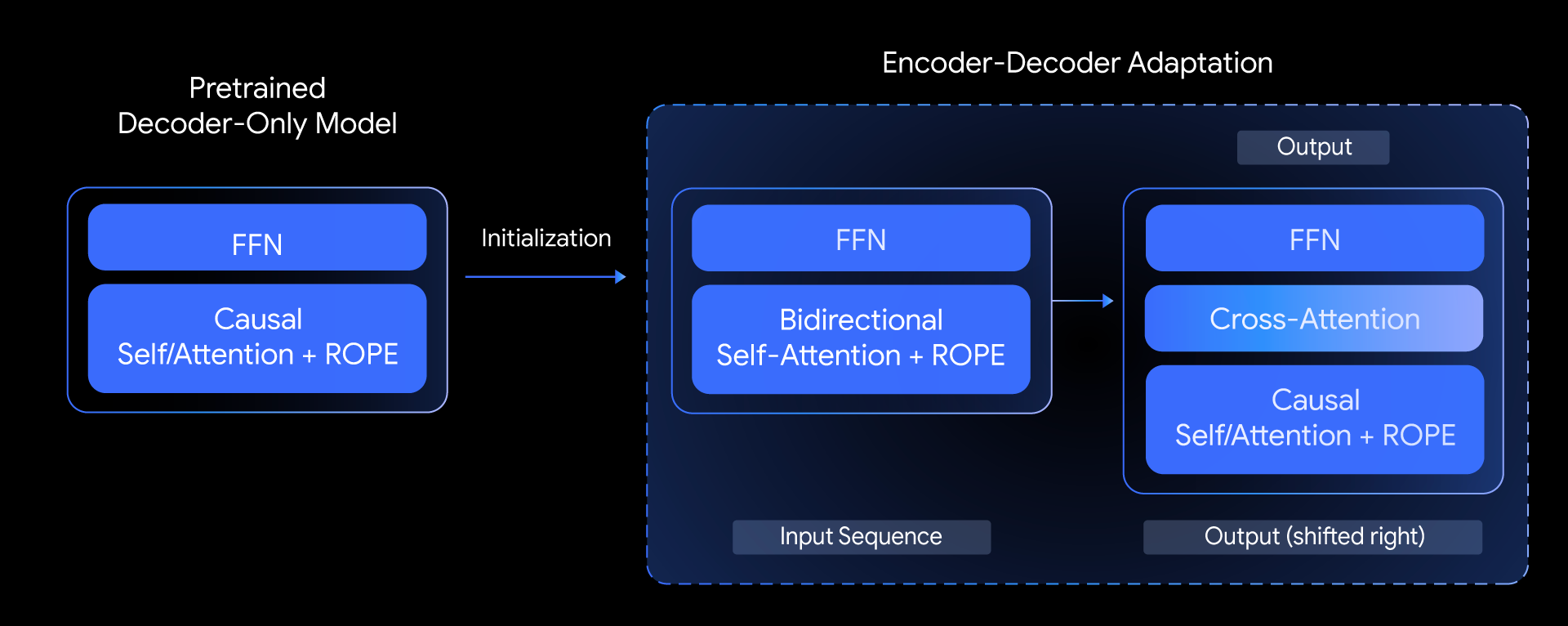
An outline of our method, exhibiting how we initialize a brand new encoder-decoder mannequin utilizing the parameters from a pretrained, decoder-only mannequin.
This adaptation methodology is very versatile, permitting for inventive combos of mannequin sizes. As an illustration, we are able to pair a big encoder with a small decoder (e.g., a 9B encoder with a 2B decoder) to create an “unbalanced” mannequin. This permits us to fine-tune the quality-efficiency trade-off for particular duties, comparable to summarization, the place a deep understanding of the enter is extra crucial than the complexity of the generated output.
In the direction of higher quality-efficiency trade-off
How does T5Gemma carry out?
In our experiments, T5Gemma fashions obtain comparable or higher efficiency than their decoder-only Gemma counterparts, almost dominating the quality-inference effectivity pareto frontier throughout a number of benchmarks, comparable to SuperGLUE which measures the standard of the realized illustration.
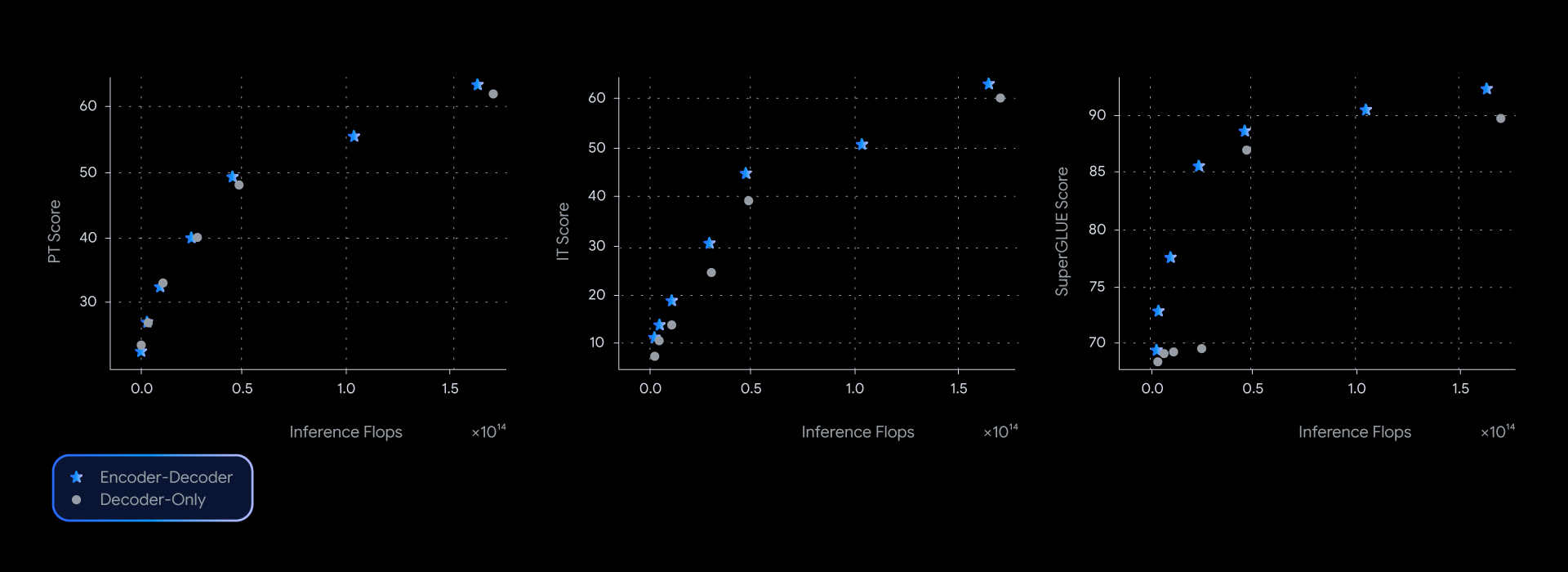
Encoder-decoder fashions persistently supply higher efficiency for a given stage of inference compute, main the quality-efficiency frontier throughout a variety of benchmarks.
This efficiency benefit is not simply theoretical; it interprets to real-world high quality and velocity too. When measuring the precise latency for GSM8K (math reasoning), T5Gemma supplied a transparent win. For instance, T5Gemma 9B-9B achieves larger accuracy than Gemma 2 9B however with an analogous latency. Much more impressively, T5Gemma 9B-2B delivers a major accuracy enhance over the 2B-2B mannequin, but its latency is sort of an identical to the a lot smaller Gemma 2 2B mannequin. Finally, these experiments showcase that encoder-decoder adaptation affords a versatile, highly effective option to steadiness throughout high quality and inference velocity.
Unlocking foundational and fine-tuned capabilities
May encoder-decoder LLMs have comparable capabilities to decoder-only fashions?
Sure, T5Gemma exhibits promising capabilities each earlier than and after instruction tuning.
After pre-training, T5Gemma achieves spectacular good points on complicated duties that require reasoning. As an illustration, T5Gemma 9B-9B scores over 9 factors larger on GSM8K (math reasoning) and 4 factors larger on DROP (studying comprehension) than the unique Gemma 2 9B mannequin. This sample demonstrates that the encoder-decoder structure, when initialized by way of adaptation, has the potential to create a extra succesful, performant foundational mannequin.
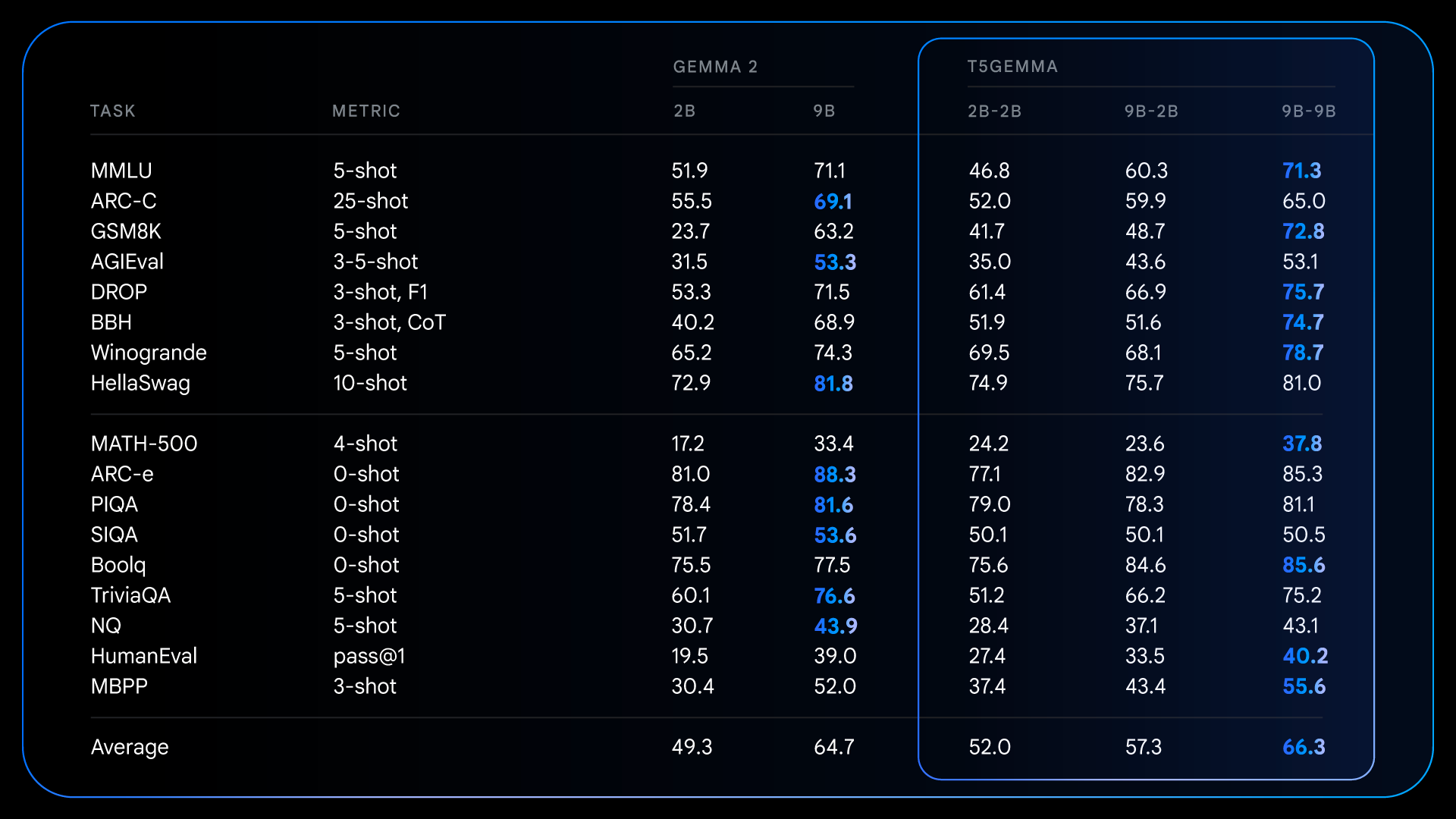
Detailed outcomes for pretrained fashions, illustrating how tailored fashions have important good points on a number of reasoning-intensive benchmarks in comparison with decoder-only Gemma 2.
These foundational enhancements from pre-training set the stage for much more dramatic good points after instruction tuning. For instance, evaluating Gemma 2 IT to T5Gemma IT, the efficiency hole widens considerably throughout the board. T5Gemma 2B-2B IT sees its MMLU rating soar by almost 12 factors over the Gemma 2 2B, and its GSM8K rating will increase from 58.0% to 70.7%. The tailored structure not solely probably supplies a greater place to begin but in addition responds extra successfully to instruction-tuning, finally resulting in a considerably extra succesful and useful closing mannequin.
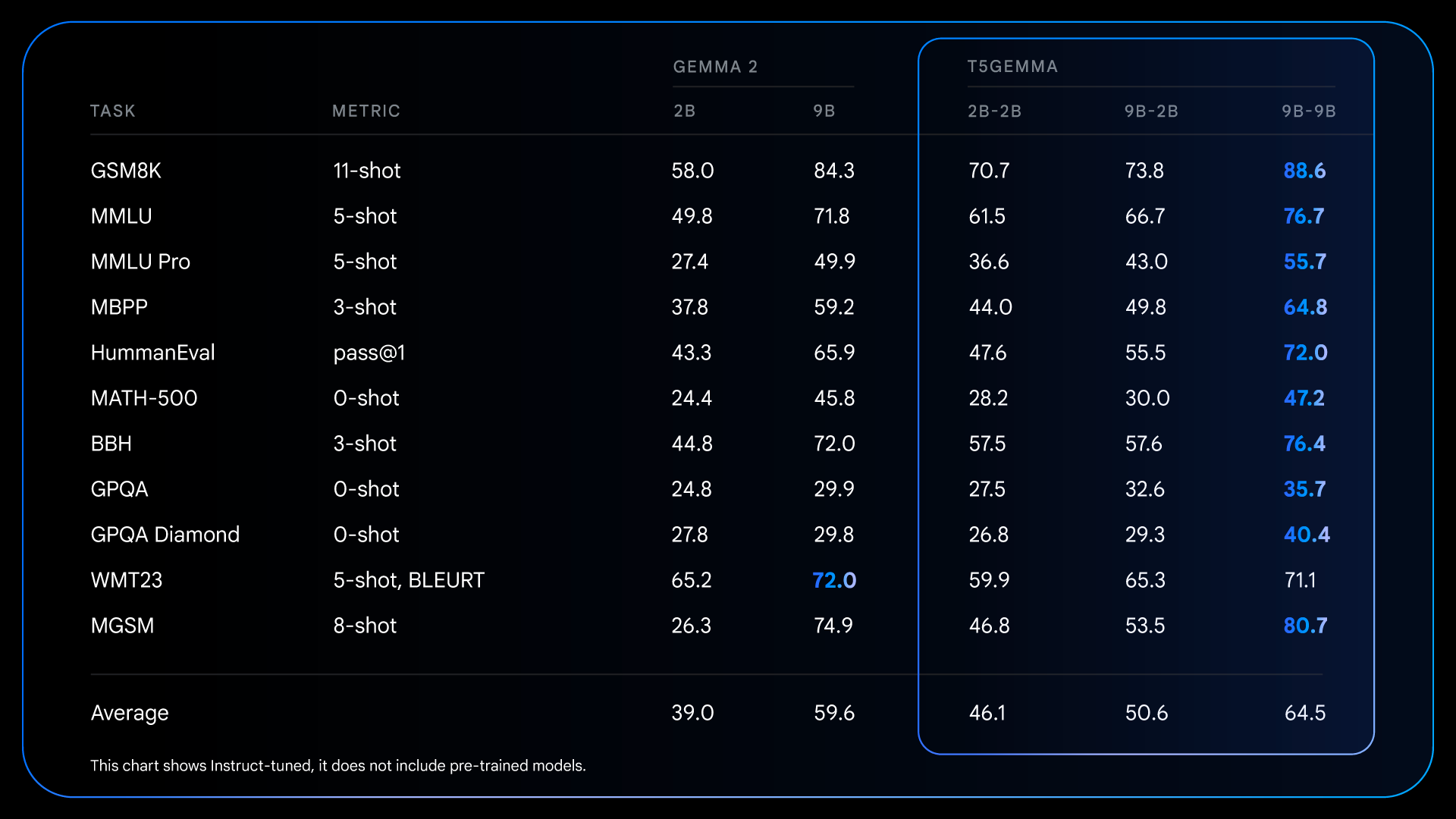
Detailed outcomes for fine-tuned + RLHFed fashions, illustrating the capabilities of post-training to considerably amplify the efficiency benefits of the encoder-decoder structure.
Discover our fashions: Releasing T5Gemma checkpoints
We’re very excited to current this new methodology of constructing highly effective, basic goal encoder-decoder fashions by adapting from pretrained decoder-only LLMs like Gemma 2. To assist speed up additional analysis and permit the group to construct on this work, we’re excited to launch a set of our T5Gemma checkpoints.
The discharge contains:
- A number of Sizes: Checkpoints for T5-sized fashions (Small, Base, Massive, and XL), the Gemma 2-based fashions (2B and 9B), in addition to a further mannequin in between T5 Massive and T5 XL.
- A number of Variants: Pretrained and instruction-tuned fashions.
- Versatile Configurations: A strong and environment friendly unbalanced 9B-2B checkpoint to discover the trade-offs between encoder and decoder dimension.
- Totally different Coaching Aims: Fashions educated with both PrefixLM or UL2 goals to supply both state-of-the-art generative efficiency or illustration high quality.
We hope these checkpoints will present a beneficial useful resource for investigating mannequin structure, effectivity, and efficiency.
Getting began with T5Gemma
We will not wait to see what you construct with T5Gemma. Please see the next hyperlinks for extra info:
- Study in regards to the analysis behind this challenge by studying the paper.
- Discover the fashions capabilities or fine-tune them on your personal use circumstances with the Colab pocket book.
🔥 Need the most effective instruments for AI advertising? Take a look at GetResponse AI-powered automation to spice up what you are promoting!
{kind=link}