🚀 Able to supercharge your AI workflow? Attempt ElevenLabs for AI voice and speech technology!
On this article, you’ll learn to construct a easy semantic search engine utilizing sentence embeddings and nearest neighbors.
Subjects we’ll cowl embrace:
- Understanding the restrictions of keyword-based search.
- Producing textual content embeddings with a sentence transformer mannequin.
- Implementing a nearest-neighbor semantic search pipeline in Python.
Let’s get began.
Construct Semantic Search with LLM Embeddings
Picture by Editor
Introduction
Conventional search engines like google have traditionally relied on key phrase search. In different phrases, given a question like “greatest temples and shrines to go to in Fukuoka, Japan”, outcomes are retrieved based mostly on key phrase matching, such that textual content paperwork containing co-occurrences of phrases like “temple”, “shrine”, and “Fukuoka” are deemed most related.
Nevertheless, this classical method is notoriously inflexible, because it largely depends on precise phrase matches and misses different necessary semantic nuances resembling synonyms or different phrasing — for instance, “younger canine” as an alternative of “pet”. In consequence, extremely related paperwork could also be inadvertently omitted.
Semantic search addresses this limitation by specializing in which means moderately than precise wording. Giant language fashions (LLMs) play a key function right here, as a few of them are educated to translate textual content into numerical vector representations referred to as embeddings, which encode the semantic info behind the textual content. When two texts like “small canines are very curious by nature” and “puppies are inquisitive by nature” are transformed into embedding vectors, these vectors will likely be extremely related as a result of their shared which means. In the meantime, the embedding vectors for “puppies are inquisitive by nature” and “Dazaifu is a signature shrine in Fukuoka” will likely be very totally different, as they characterize unrelated ideas.
Following this precept — which you’ll discover in additional depth right here — the rest of this text guides you thru the total technique of constructing a compact but environment friendly semantic search engine. Whereas minimalistic, it performs successfully and serves as a place to begin for understanding how trendy search and retrieval techniques, resembling retrieval augmented technology (RAG) architectures, are constructed.
The code defined beneath might be run seamlessly in a Google Colab or Jupyter Pocket book occasion.
Step-by-Step Information
First, we make the required imports for this sensible instance:
|
import pandas as pd import json from pydantic import BaseModel, Area from openai import OpenAI from google.colab import userdata from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.preprocessing import StandardScaler |
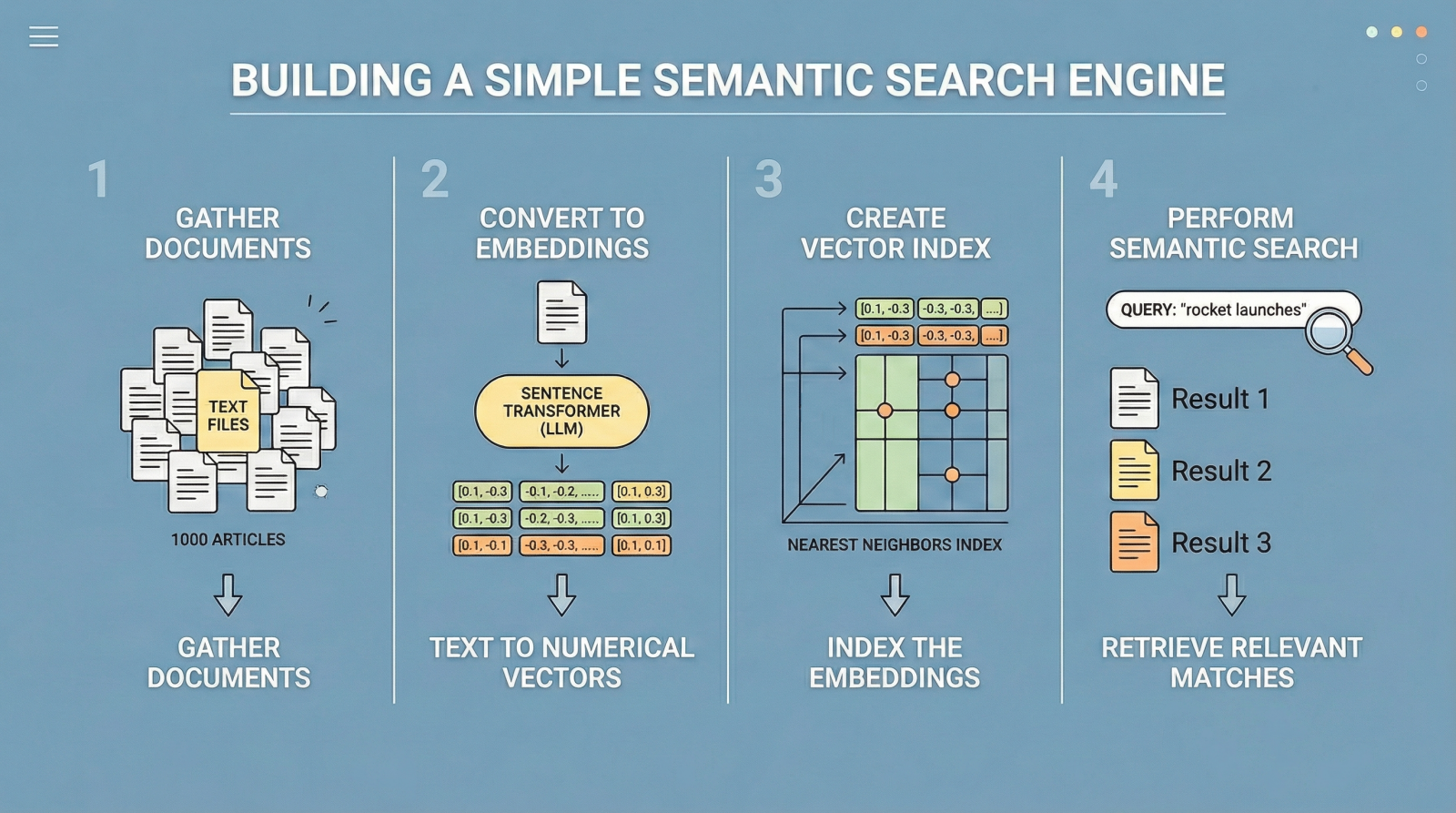
We’ll use a toy public dataset referred to as "ag_news", which incorporates texts from information articles. The next code masses the dataset and selects the primary 1000 articles.
|
from datasets import load_dataset from sentence_transformers import SentenceTransformer from sklearn.neighbors import NearestNeighbors |
We now load the dataset and extract the "textual content" column, which incorporates the article content material. Afterwards, we print a brief pattern from the primary article to examine the info:
|
print(“Loading dataset…”) dataset = load_dataset(“ag_news”, break up=“prepare[:1000]”)
# Extract the textual content column right into a Python listing paperwork = dataset[“text”]
print(f“Loaded {len(paperwork)} paperwork.”) print(f“Pattern: {paperwork[0][:100]}…”) |
The following step is to acquire embedding vectors (numerical representations) for our 1000 texts. As talked about earlier, some LLMs are educated particularly to translate textual content into numerical vectors that seize semantic traits. Hugging Face sentence transformer fashions, resembling "all-MiniLM-L6-v2", are a standard selection. The next code initializes the mannequin and encodes the batch of textual content paperwork into embeddings.
|
print(“Loading embedding mannequin…”) mannequin = SentenceTransformer(“all-MiniLM-L6-v2”)
# Convert textual content paperwork into numerical vector embeddings print(“Encoding paperwork (this will likely take a number of seconds)…”) document_embeddings = mannequin.encode(paperwork, show_progress_bar=True)
print(f“Created {document_embeddings.form[0]} embeddings.”) |
Subsequent, we initialize a NearestNeighbors object, which implements a nearest-neighbor technique to seek out the ok most related paperwork to a given question. By way of embeddings, this implies figuring out the closest vectors (smallest angular distance). We use the cosine metric, the place extra related vectors have smaller cosine distances (and better cosine similarity values).
|
search_engine = NearestNeighbors(n_neighbors=5, metric=“cosine”)
search_engine.match(document_embeddings) print(“Search engine is prepared!”) |
The core logic of our search engine is encapsulated within the following perform. It takes a plain-text question, specifies what number of high outcomes to retrieve through top_k, computes the question embedding, and retrieves the closest neighbors from the index.
The loop contained in the perform prints the top-ok outcomes ranked by similarity:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
def semantic_search(question, top_k=3): # Embed the incoming search question query_embedding = mannequin.encode([query])
# Retrieve the closest matches distances, indices = search_engine.kneighbors(query_embedding, n_neighbors=top_k)
print(f“n🔍 Question: ‘{question}'”) print(“-“ * 50)
for i in vary(top_k): doc_idx = indices[0][i] # Convert cosine distance to similarity (1 – distance) similarity = 1 – distances[0][i]
print(f“End result {i+1} (Similarity: {similarity:.4f})”) print(f“Textual content: {paperwork[int(doc_idx)][:150]}…n”) |
And that’s it. To check the perform, we are able to formulate a few instance search queries:
|
semantic_search(“Wall road and inventory market tendencies”) semantic_search(“House exploration and rocket launches”) |
The outcomes are ranked by similarity (truncated right here for readability):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
🔍 Question: ‘Wall road and inventory market tendencies’ ————————————————————————— End result 1 (Similarity: 0.6258) Textual content: Shares Increased Regardless of Hovering Oil Costs NEW YORK – Wall Avenue shifted greater Monday as cut price hunters shrugged off skyrocketing oil costs and boug...
End result 2 (Similarity: 0.5586) Textual content: Shares Sharply Increased on Dip in Oil Costs NEW YORK – A drop in oil costs and upbeat outlooks from Wal–Mart and Lowe‘s prompted new bargain-hunting o…
End result 3 (Similarity: 0.5459) Textual content: Methods for a Sideways Market (Reuters) Reuters – The bulls and the bears are on this collectively, scratching their heads and questioning what’s going t...
🔍 Question: ‘House exploration and rocket launches’ ————————————————————————— End result 1 (Similarity: 0.5803) Textual content: Redesigning Rockets: NASA House Propulsion Finds a New Residence (SPACE.com) SPACE.com – Whereas the exploration of the Moon and different planets in our photo voltaic s...
End result 2 (Similarity: 0.5008) Textual content: Canadian Staff Joins Rocket Launch Contest (AP) AP – The #36;10 million competitors to ship a personal manned rocket into house began trying extra li…
End result 3 (Similarity: 0.4724) Textual content: The Subsequent Nice House Race: SpaceShipOne and Wild Fireplace to Go For the Gold (SPACE.com) SPACE.com – A piloted rocket ship race to declare a #36;10 million… |
Abstract
What we’ve constructed right here might be seen as a gateway to retrieval augmented technology techniques. Whereas this instance is deliberately easy, semantic search engines like google like this manner the foundational retrieval layer in trendy architectures that mix semantic search with massive language fashions.
Now that you know the way to construct a primary semantic search engine, chances are you’ll wish to discover retrieval augmented technology techniques in additional depth.
🔥 Need the most effective instruments for AI advertising and marketing? Try GetResponse AI-powered automation to spice up your online business!
{kind=link}