🚀 Able to supercharge your AI workflow? Strive ElevenLabs for AI voice and speech era!
On this article, you’ll be taught what agentic RAG is, the way it differs from conventional RAG, and when to make use of it.
Matters we’ll cowl embody:
- The important thing limitations of conventional RAG pipelines and what brokers add to handle them.
- How the agentic retrieval loop works, together with question decomposition, multi-hop chaining, and self-correction.
- Superior architectures like Graph RAG, reflection, and reminiscence, together with the manufacturing tradeoffs that include them.
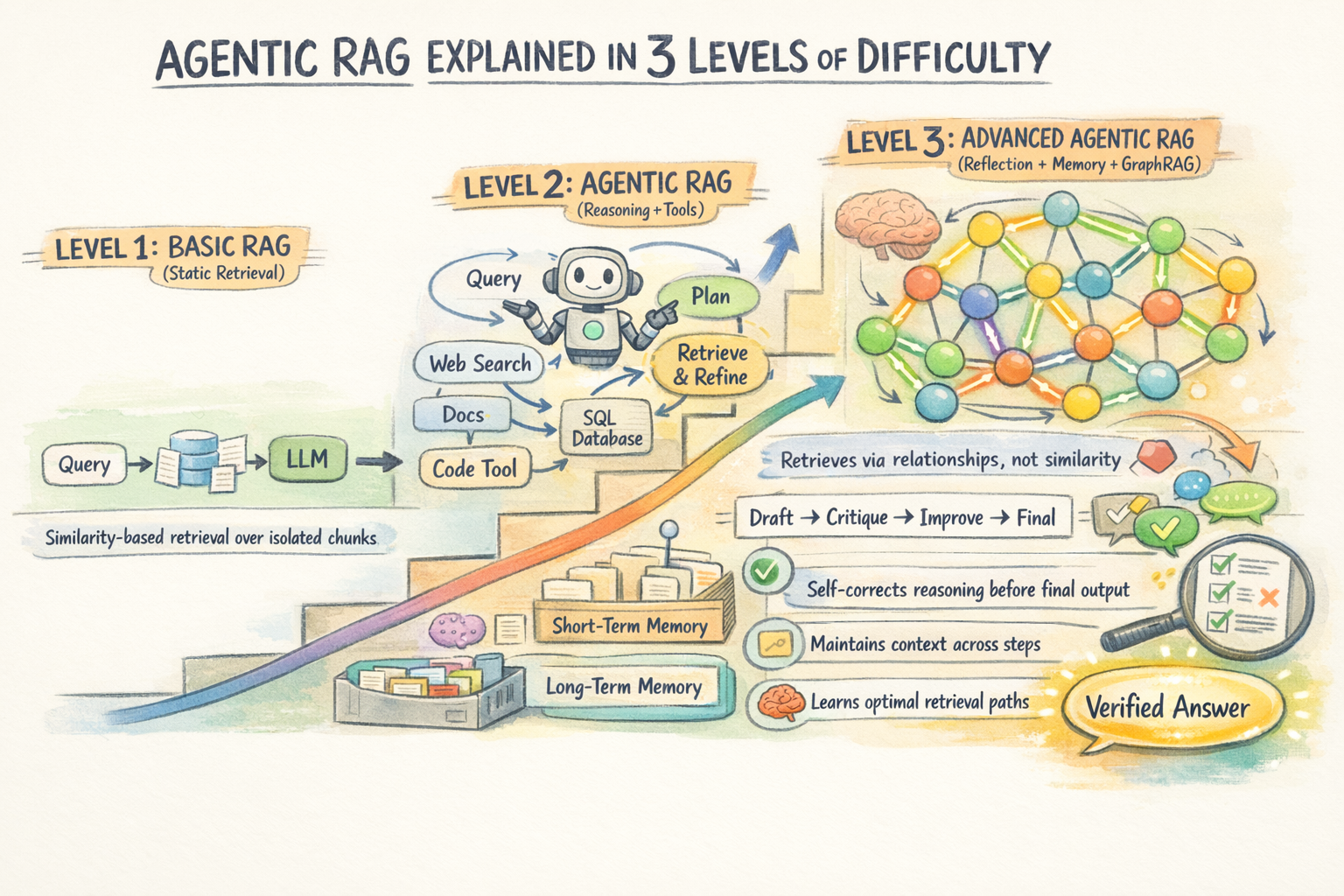
Agentic RAG Defined in 3 Ranges of Issue
Introduction
Conventional Retrieval-Augmented Technology (RAG) retrieves info as soon as and generates a response primarily based on that single end result. This strategy works effectively for easy, clearly outlined questions. Nonetheless, it begins to interrupt down when a activity requires pulling info from a number of sources, reasoning throughout paperwork, or refining incomplete outcomes.
A fundamental RAG pipeline has no built-in approach to retry, regulate its retrieval technique, or validate the standard of what it retrieved. Because of this, it may possibly battle with extra complicated queries the place iteration and verification are necessary. Agentic RAG extends the standard RAG pipeline by introducing autonomous AI brokers into the method. As a substitute of a single retrieval move, an agent decomposes the question, routes every half to the fitting supply, checks what it will get again, and iterates till it has sufficient grounded context to generate a dependable reply.
This text covers agentic RAG at three ranges. Degree 1 contrasts it with conventional RAG and explains the core capabilities brokers add. Degree 2 will get into how the retrieval loop truly works: decomposition, multi-hop chaining, and self-correction. Degree 3 covers extra superior architectures like Graph RAG and the manufacturing tradeoffs that matter at scale.
Degree 1: Making Sense of the “Agentic” in Agentic RAG
The Limitations of Conventional RAG
Conventional RAG follows a set sequence. The retriever runs as soon as, produces a set of chunks, and people chunks go to the LLM. There isn’t any reasoning about whether or not the retrieved context is definitely helpful, no mechanism to strive once more if retrieval misses the mark, and no potential to tug from a number of sources or use exterior instruments. It’s a one-shot resolution.
This creates particular failure modes. For a question like “Evaluate our Q3 2025 gross sales with Q1 2026 efficiency and summarize the important thing danger elements from our newest SEC submitting,” a static RAG pipeline retrieves no matter chunks occurred to be most much like that mixed question — virtually definitely a mishmash that doesn’t cleanly handle both half.
The pipeline has no approach to decompose the query, retrieve totally different info for every half, and synthesize a coherent reply.
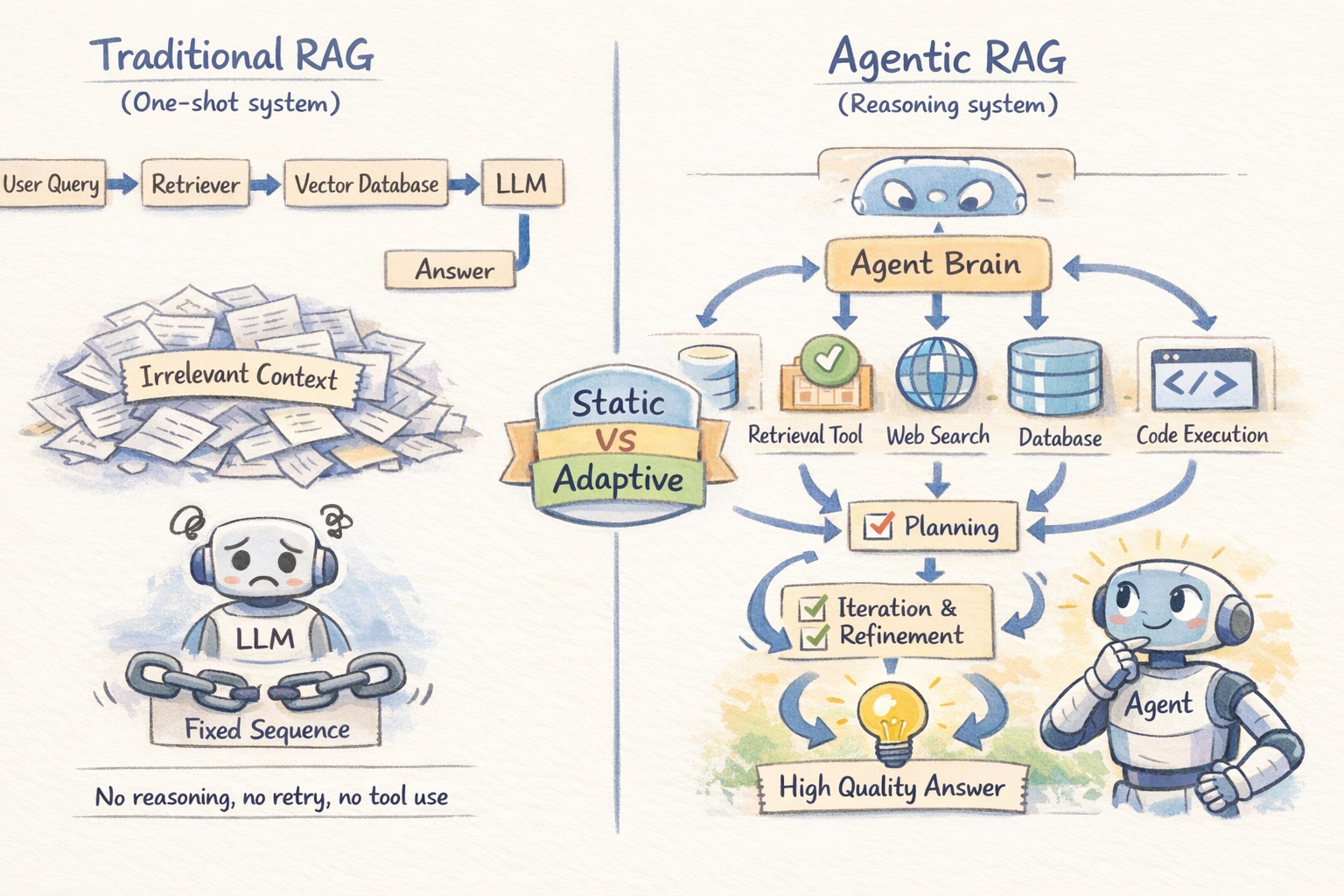
Primary RAG vs. Agentic RAG
What Brokers Add
An AI agent is an LLM-powered system with a task, a activity, and entry to instruments — and extra importantly, the flexibility to cause about what to do subsequent primarily based on what it observes. The important thing capabilities brokers convey to RAG are planning, instrument use, and iterative refinement:
Planning lets the agent break a fancy question into subtasks and determine what info is required and in what order.
Instrument use permits retrieval past vector shops, together with internet search, SQL databases, APIs, and code execution — choosing the proper instrument per activity.
Iterative refinement allows the agent to guage outcomes, retry searches, and resolve conflicts by retrieving extra context, enhancing reliability over one-shot retrieval.
Degree 2: Understanding How the Agentic Retrieval Loop Works
Question Decomposition and Supply Routing
The very first thing an agentic RAG system does with a fancy question is break it aside. Somewhat than firing the complete question at a single retrieval supply, the agent identifies the distinct info wants embedded in it and plans a retrieval technique for each. That is question decomposition, and it’s what makes agentic RAG qualitatively totally different from static pipelines.
As soon as decomposed, every sub-question is routed to essentially the most appropriate supply. The agent acts as a router throughout vector shops, databases, internet search, and information bases. Routing is dependent upon question kind: factual lookups go to structured knowledge, semantic queries go to paperwork, and time-sensitive questions go to internet search. A single request could mix a number of sources in sequence.
Multi-Hop Retrieval
Many queries require multi-hop reasoning, the place info should be related throughout a number of paperwork. For instance, understanding an organization’s authorized publicity could require linking filings, case legislation, and compliance data that aren’t retrieved collectively in a single step.
Agentic techniques clear up this by chaining retrievals: every end result informs the subsequent question. The agent iterates — retrieving context, figuring out gaps, refining queries — till sufficient proof is gathered for a dependable reply.
Techniques like RQ-RAG formalize this by decomposing multi-hop queries into latent sub-questions upfront; RAG-Fusion takes a parallel strategy, producing a number of reformulations of the identical question and merging outcomes utilizing reciprocal rank fusion to enhance recall when a single formulation would miss related content material.
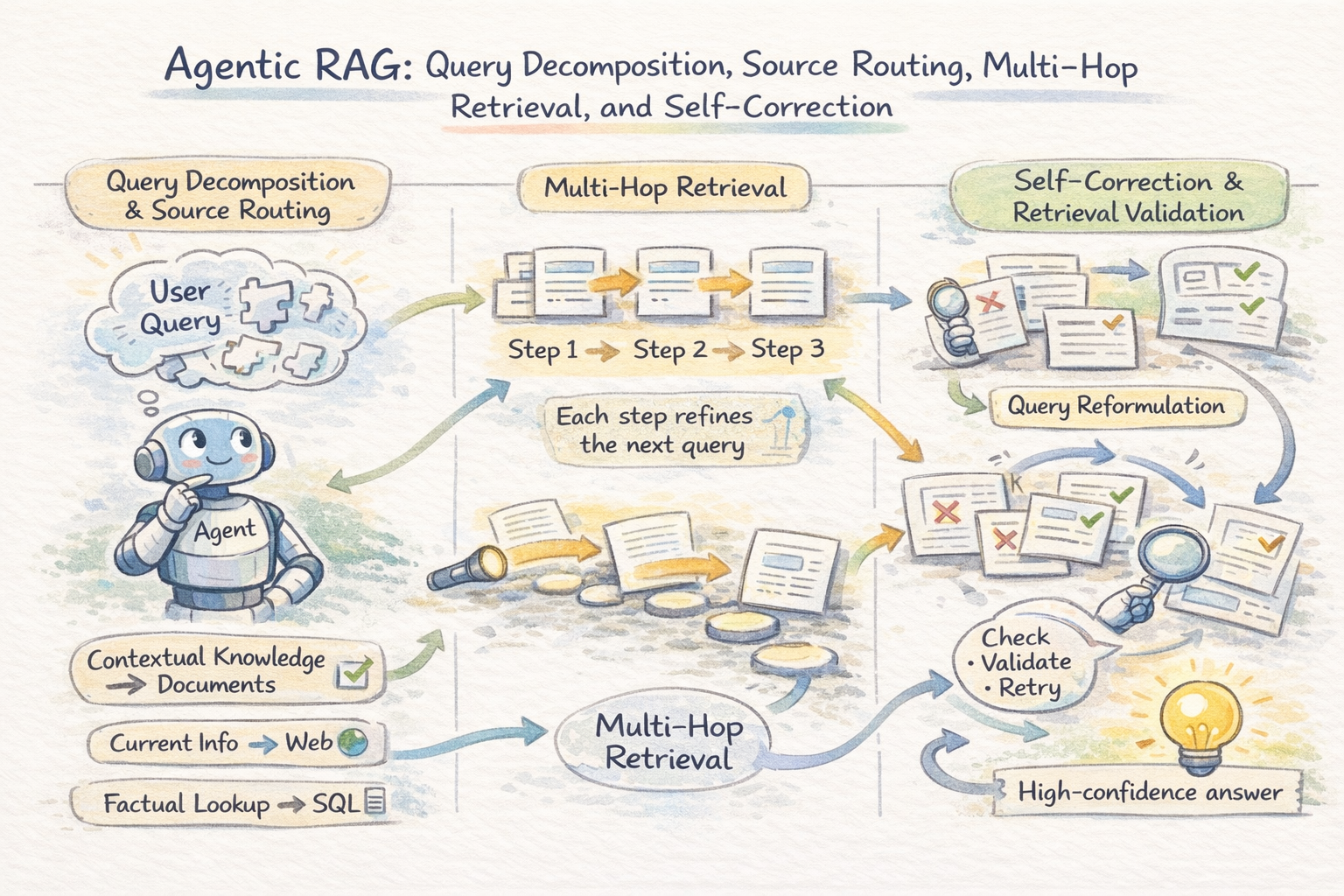
An outline of agentic retrieval loop
Self-Correction and Retrieval Validation
In a static pipeline, retrieved context is handed on to the LLM, which can not confirm its relevance and will generate incorrect however believable solutions from loosely associated chunks.
Agentic techniques add validation steps: the agent checks relevance, detects contradictions, and re-queries when wanted. Irrelevant or weak proof will not be handed ahead. This self-correction loop is a key distinction from static RAG, decreasing hallucinations by treating retrieved knowledge as proof to guage somewhat than fact to imagine.
Degree 3: Transferring to Superior Agentic RAG Architectures and Manufacturing Tradeoffs
Graph RAG and Structured Data
Vector search in a vector database treats paperwork as unbiased chunks ranked by embedding similarity. This works when related info is self-contained inside passages, however breaks down when queries require reasoning over relationships between entities — the place the secret’s how entities throughout paperwork join, not simply what every doc says.
Graph RAG builds a information graph from paperwork and retrieves by way of graph traversal as a substitute of embedding similarity. For domains the place info is inherently relational — authorized analysis, healthcare diagnostics, monetary publicity evaluation — Graph RAG persistently outperforms flat retrieval on complicated reasoning duties.
It improves efficiency on relationship-heavy queries however is pricey to construct and keep. It’s best suited to secure, high-value knowledge and isn’t effectively suited for easy or fast-changing datasets.
Learn GraphRAG and Agentic Structure: Sensible Experimentation with Neo4j and NeoConverse for a sensible strategy to integrating Graph RAG in agentic purposes.
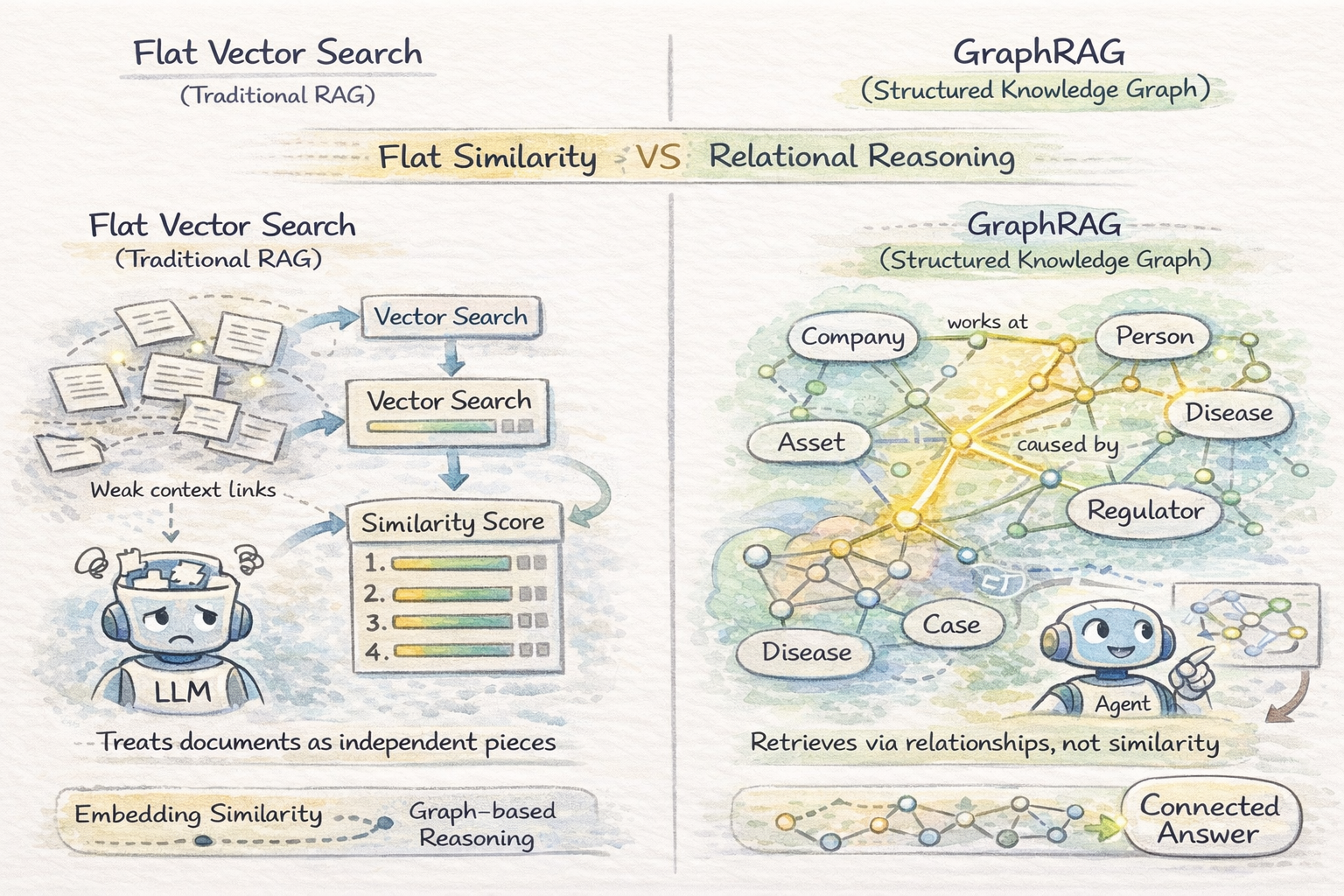
Vector Similarity Search vs Graph RAG
Reflection and Reminiscence
Superior agentic RAG techniques add two mechanisms above the retrieval loop.
Reflection lets the agent assessment its draft reply for gaps, errors, or weak assist and set off additional retrieval if wanted.
Reminiscence works at two ranges: short-term reminiscence tracks what has already been retrieved in a session, whereas long-term reminiscence learns from previous queries to enhance future retrieval effectivity.
Collectively, reflection and reminiscence push agentic RAG from a stateless retrieval loop towards one thing nearer to a reasoning system with real operational historical past.
Vector Databases vs. Graph RAG for Agent Reminiscence: When to Use Which is a helpful useful resource for deciding between Graph RAG and vector databases for agentic reminiscence.
So when is agentic RAG overkill? Agentic RAG is extra highly effective however slower and costlier than static RAG. It makes use of a number of LLM calls, so latency, token use, and failure danger all enhance with complexity. A easy rule of thumb: use static RAG for single-hop factual queries and agentic RAG for multi-step reasoning or cross-source synthesis.
Conclusion
The defining perception of agentic RAG is easy: retrieval isn’t a single well-defined step — it’s an ongoing reasoning course of. Primary RAG pipelines retrieve and generate. Agentic RAG techniques retrieve, consider, iterate, after which generate, and the distinction in output high quality on complicated queries is substantial. The tradeoffs in value and latency are actual, however for the category of questions that matter most in manufacturing, they’re value it.
For additional studying, you could discover the next assets helpful:
Completely happy studying!
🔥 Need the most effective instruments for AI advertising and marketing? Take a look at GetResponse AI-powered automation to spice up what you are promoting!
{kind=link}