🚀 Able to supercharge your AI workflow? Attempt ElevenLabs for AI voice and speech technology!
On this article, you’ll be taught what context engineering is and how one can apply it systematically to maintain AI brokers dependable, cost-efficient, and correct in manufacturing.
Matters we’ll cowl embrace:
- The way to deal with the context window as a constrained useful resource and perceive the monetary and cognitive prices of token mismanagement.
- The way to construction context layers — separating static from dynamic content material, managing dialog historical past, and designing retrieval as a finances resolution.
- The way to consider and monitor context high quality in manufacturing utilizing probe-based analysis and context-specific metrics.
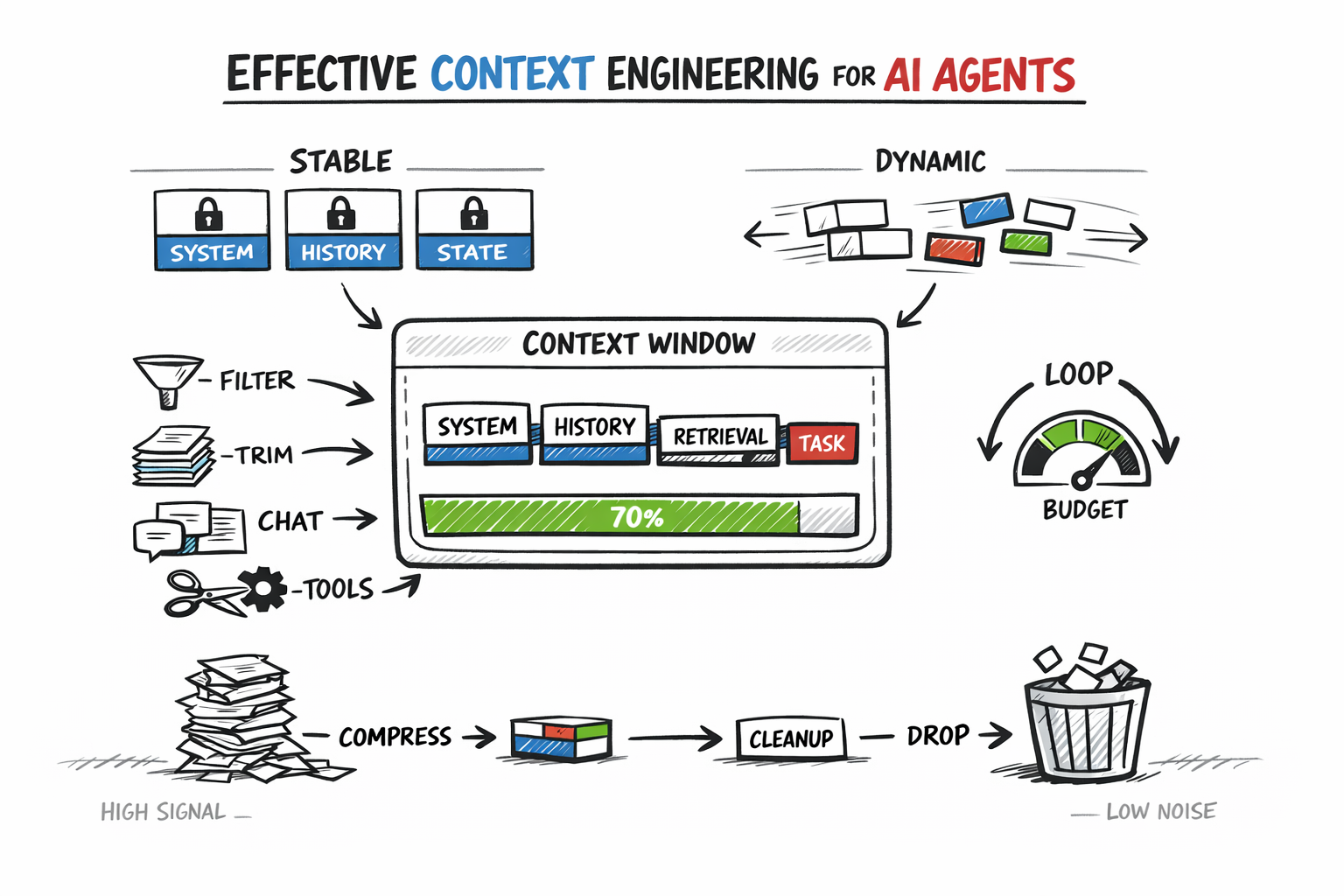
Efficient Context Engineering for AI Brokers: A Developer’s Information
Picture by Writer
Introduction
When AI brokers break down in manufacturing, the issue isn’t the mannequin. Extra typically, the context window is mismanaged: bloated with stale historical past, redundant retrieval outcomes, and uncooked device outputs that bury the sign the mannequin truly wants.
Context engineering is the observe of deciding what enters the context window, what will get compressed, what will get retrieved on demand, and what will get dropped totally. Achieved effectively, it retains each token high-signal and cuts the fee and high quality issues that come from naive context accumulation.
This text covers the core practices:
- Understanding the context window as a constrained useful resource
- Structuring and separating secure from dynamic context
- Managing historical past, retrieval, and token budgets throughout the agent loop
- Evaluating and monitoring context high quality in manufacturing
Every observe builds on the final, forming the structure that retains brokers dependable underneath actual workloads.
Treating the Context Window as a Constrained Useful resource
The context window shapes each different resolution in agentic structure. Treating it as a mere technical restrict to route round, fairly than the first design parameter, is the place most agent implementations go mistaken.
Tokens have two sorts of price: monetary and cognitive. Monetary price is direct — fashions are billed per million enter tokens, and this scales shortly in multi-step agent loops.
Cognitive price is much less apparent. Fashions don’t deal with all tokens equally. Consideration tends to prioritize data firstly and finish of the context, whereas mid-context content material is usually much less influential. Consequently, lengthy or poorly structured inputs can degrade reasoning even when they match inside the token restrict.
The psychological mannequin that helps most is treating the context window like RAM: quick and highly effective, however finite and cleared between periods. Exterior reminiscence, databases, and file programs are the disk — low cost and enormous, however requiring express retrieval to be helpful.
Good context engineering decides at every step what belongs in RAM proper now and what lives on disk till wanted. Google’s Agent Improvement Equipment (ADK) group addresses why the naive sample of appending every part into one large immediate collapses underneath three-way strain: price and latency spirals, sign degradation, and eventual overflow.
Mapping What Fills the Context Window
Most brokers have extra competing inputs than builders notice till they audit them. A manufacturing context window sometimes incorporates some mixture of:
- System directions — the agent’s function, behavioral guidelines, device descriptions, output format necessities, and few-shot examples. Largely static, making this layer a robust candidate for prefix caching.
- Dialog historical past — the working document of person turns, agent responses, device calls, and power outcomes. Usually the fastest-growing layer and the one most groups under-manage.
- Retrieved information — paperwork, database data, or reminiscence gadgets fetched from exterior shops. Retrieval programs can return relevant-but-redundant content material, and each chunk consumes a finances that would maintain one thing extra helpful.
- Working state — intermediate outcomes, scratchpad reasoning, process progress. Essential for multi-step coherence, however costly if saved as verbose reasoning traces.
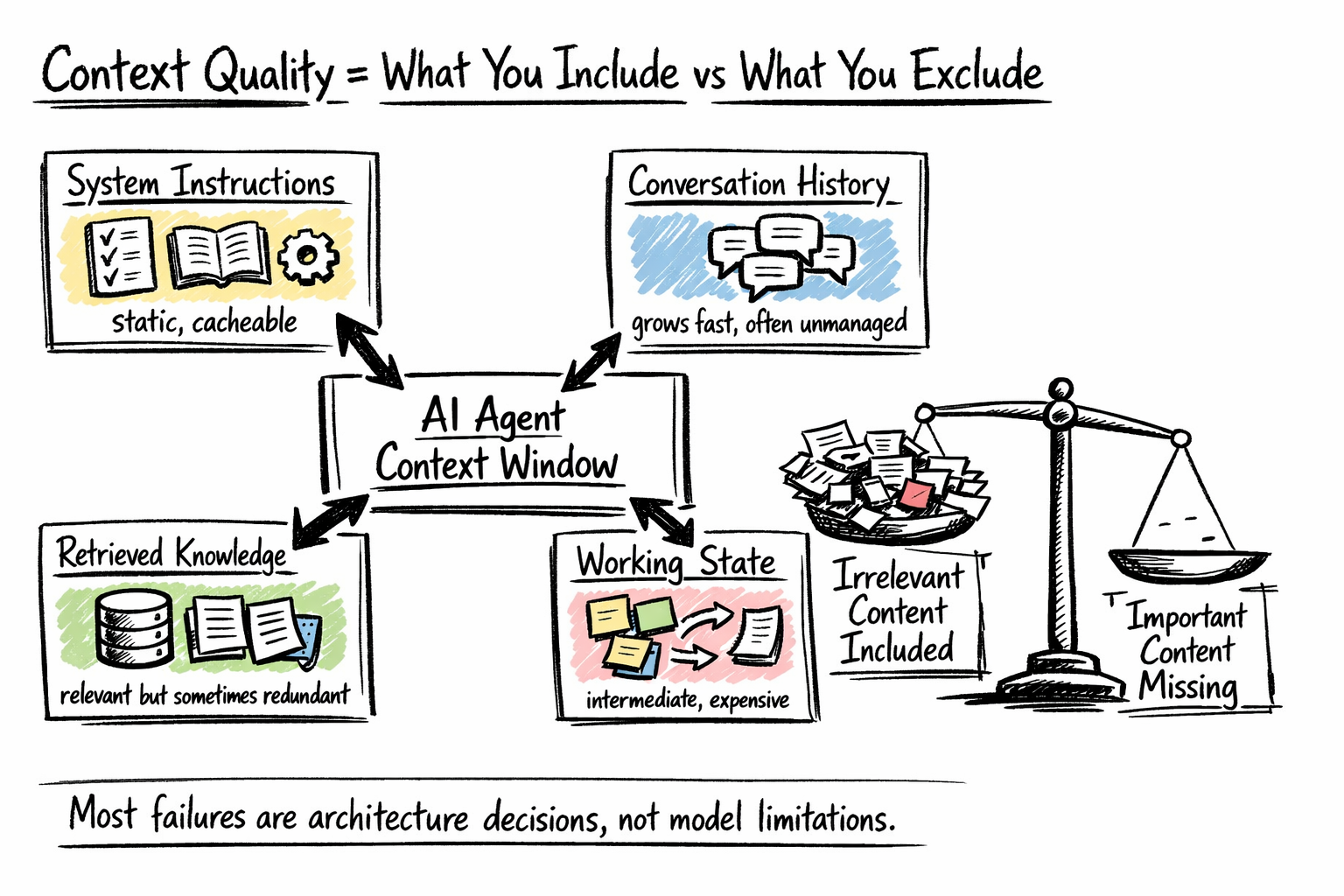
What goes into the context window
The objective of this audit is to know the trade-offs throughout layers, to not reduce each. Most context high quality issues in manufacturing hint again to one in every of two failures: together with content material irrelevant to the present step, or excluding content material that issues. Each are structure choices, not mannequin choices.
Separating Static from Dynamic Context
One of many highest-value structural choices in context engineering is the cut up between content material that stays mounted throughout requests and content material that modifications with every flip.
Static context: system directions, agent id, device schemas, and glued guidelines positioned on the entrance of the immediate. This permits prefix caching, the place unchanged prefixes are reused as a substitute of recomputed every name.
Dynamic context: present person enter, current device outputs, and retrieved paperwork within the variable suffix. This layer ought to keep minimal, containing solely what’s wanted for the present reasoning step.
The sensible implementation is a two-pass context meeting pipeline.
- The primary go masses static context: system immediate, cached directions, long-lived summaries.
- The second go injects dynamic context: present process state, contemporary retrieval outcomes, current historical past.
This separation additionally simplifies debugging. Sudden habits could be traced to both the static configuration — which is usually a immediate engineering drawback — or the dynamic state, which factors to a retrieval or historical past administration drawback.
Managing Dialog Historical past
Dialog historical past is the context part brokers most frequently deal with poorly. Most frameworks merely append every new flip and resend the total historical past. This works for brief periods, however long-running brokers accumulate price and high quality points.
Context bloat occurs when previous device outputs, resolved errors, and outdated choices stay within the immediate, consuming tokens with out including worth. Context poisoning happens when a mannequin’s earlier mistake is preserved and handled as reality, inflicting compounding errors as later reasoning builds on it. See How Lengthy Contexts Fail for extra element.
A easy technique like recency truncation — holding solely the final N turns — is cost-effective however loses long-term state. A stronger method is rolling summarization: periodically compress older exchanges into a brief abstract capturing choices, makes an attempt, and present state.
Probably the most sturdy technique is anchored iterative summarization, the place a structured session-state doc — intent, choices, actions, subsequent steps — is repeatedly up to date, preserving that means whereas stopping context overflow.
Designing Retrieval as a Finances Choice
Retrieval lets brokers entry information that doesn’t match within the context window. A standard mistake is treating it as a easy upstream step — retrieve chunks, inject them, and proceed — with out asking how a lot of the context finances retrieval ought to truly eat, or when it’s value it.
Token price is usually underestimated. In multi-retrieval workflows, prices stack shortly. Submit-retrieval filtering — scoring and choosing solely related outcomes earlier than injecting them into context — is among the highest-leverage optimizations.
Construction issues as a lot as choice. Semantic chunking, which splits paperwork alongside pure subject boundaries as a substitute of mounted sizes, performs higher as a result of it preserves that means and coherence. Hybrid retrieval combines semantic search with key phrase or metadata filters, dealing with circumstances pure embeddings miss. For instance, “billing points within the final 30 days” requires each semantic relevance and a time constraint; neither method alone is enough.
One design resolution value making explicitly: ought to retrieval fireplace robotically earlier than each agent flip, or ought to the agent invoke it as a device when it acknowledges a necessity?
- Computerized retrieval is easier however injects tokens whether or not or not they’re helpful.
- Agent-controlled retrieval produces extra focused queries and fires on the proper second within the reasoning chain, at the price of requiring the mannequin to acknowledge when retrieval would assist.
For many manufacturing programs, agent-controlled retrieval is the higher default as soon as the system is secure.
Budgeting Tokens Throughout the Full Agent Loop
Particular person context choices solely resolve a part of the issue. In multi-step agent loops, tokens accumulate throughout turns, so budgeting should deal with the total run as the fee unit.
Tokens primarily go to system prompts and power outputs. Device responses — particularly search and API outcomes — are sometimes the most important price. Filtering and trimming them at ingestion is more practical than compressing later; solely hold what’s wanted for the following step.
Intention for roughly 60–80% context utilization fairly than maxing out capability. Monitoring this in manufacturing helps catch finances points early. Use dynamic allocation: easy duties get minimal context, whereas advanced multi-step duties get extra. This balances price and functionality.
Evaluating Context High quality in Manufacturing
Context engineering failures are sometimes invisible in normal evaluations. An agent could carry out effectively in brief take a look at periods however degrade in longer ones, with failures incorrectly attributed to reasoning as a substitute of context administration.
A sensible solution to isolate that is probe-based analysis: after compression or retrieval steps, ask focused questions that require particular saved data. Appropriate responses point out the related context was preserved; incorrect ones reveal points in compression or retrieval high quality. Manufacturing facility.ai’s analysis framework makes use of three probe sorts:
- Recall probes: can the agent keep in mind particular info?
- Artifact probes: does the agent know what recordsdata it has modified?
- Continuation probes: can the agent choose up a multi-step process the place it left off?
Listed below are some context-specific manufacturing metrics value monitoring:
- Context utilization price — proportion of finances truly used
- Compression ratio — token discount from summarization
- Retrieval precision — are retrieved chunks truly being utilized by the mannequin, or ignored after injection?
Monitoring for context drift in long-running periods can also be value instrumenting explicitly. Sign indicators embrace the agent re-reading recordsdata it already processed, re-stating choices it already made, or regularly reframing the duty away from the unique person intent. These patterns seem in step-level traces earlier than they floor in output high quality.
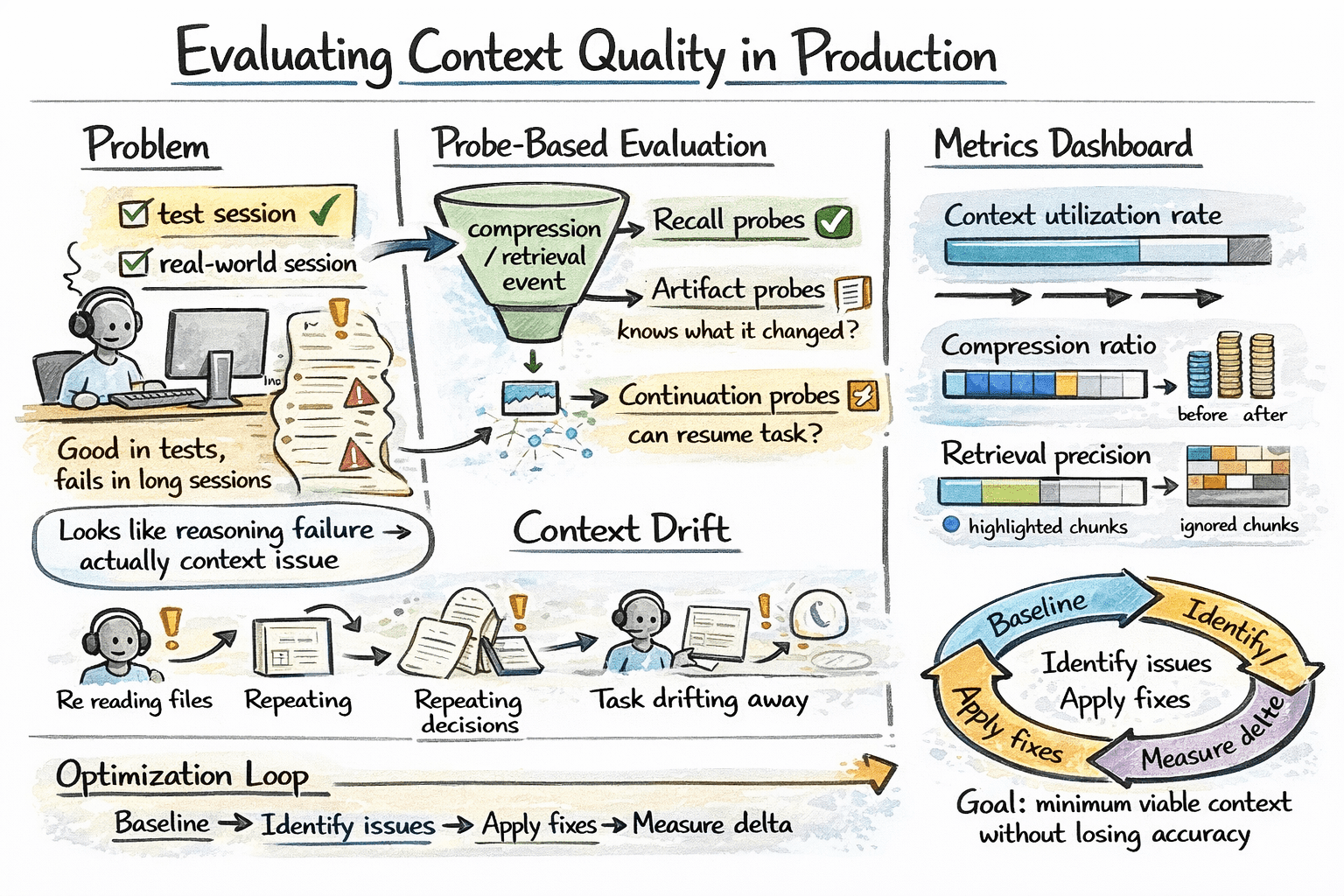
Evaluating context high quality in manufacturing
The proper optimization cycle is: set baseline metrics on actual periods, discover high-cost or low-quality segments, apply focused fixes, and measure influence.
Over-compression can save tokens however damage accuracy, shifting the issue as a substitute of fixing it. The objective is the minimal viable context that also lets the agent full its process accurately.
Wrapping Up
Context engineering spans all components of agent design: context content material, historical past administration, compression, retrieval, and token budgeting. Every alternative must be deliberate. Tooling is enhancing with prefix caching, higher summarization, and stronger retrieval. The core rule stays the identical: deal with context as scarce, embrace solely what’s vital, and validate towards actual habits. Right here’s an summary of the important thing ideas lined:
| Idea | Abstract |
|---|---|
| Context Engineering | Systematic design of what enters the context window to enhance reliability, accuracy, and price effectivity. |
| Context Window as Useful resource | Deal with tokens as restricted compute and cognitive finances with each monetary price and a focus constraints. |
| Context Construction | Consists of system directions, dialog historical past, retrieved information, and dealing state; cut up into static (mounted, cacheable) and dynamic (task-dependent) layers. |
| Historical past Administration | Keep away from uncooked accumulation; use truncation, summarization, or structured state monitoring to forestall bloat and error propagation. |
| Retrieval Design | Deal with retrieval as a budgeted operation utilizing filtering, semantic chunking, and agent-controlled triggering. |
| Token Budgeting | Handle tokens throughout full agent loops; prioritize trimming device outputs and preserve ~60–80% utilization. |
| Analysis & Key Metrics | Use probe-based exams (recall, artifact, continuation) and monitor utilization, compression ratio, retrieval precision, and context drift. |
And listed below are a few useful sources for additional studying:
🔥 Need one of the best instruments for AI advertising and marketing? Take a look at GetResponse AI-powered automation to spice up your enterprise!
{kind=link}