🚀 Able to supercharge your AI workflow? Attempt ElevenLabs for AI voice and speech era!
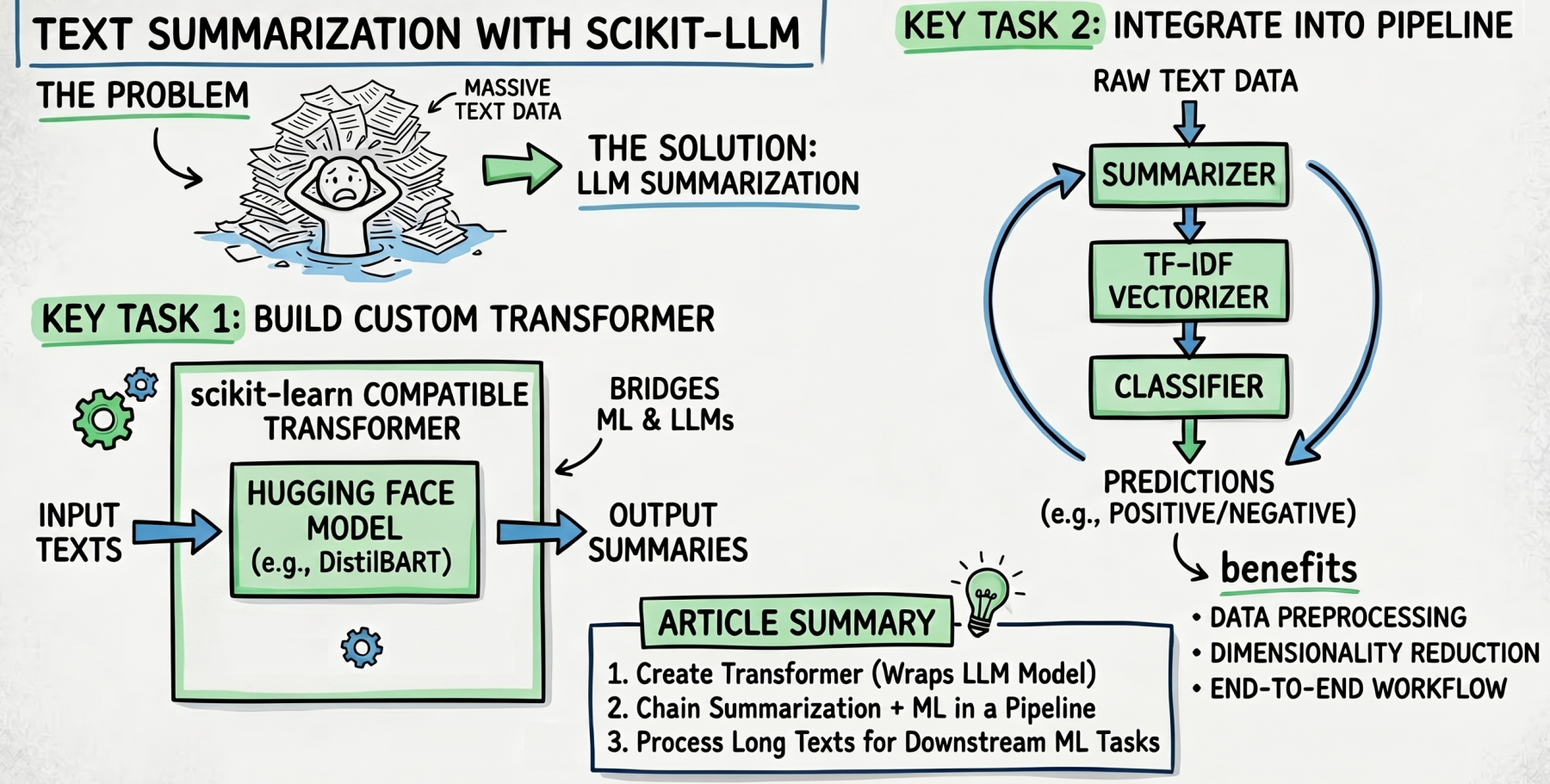
On this article, you’ll discover ways to use scikit-LLM’s textual content summarization characteristic to deal with massive volumes of textual content in machine studying pipelines.
Matters we’ll cowl embody:
- Methods to construct a customized scikit-learn-compatible transformer that wraps a Hugging Face summarization mannequin.
- Methods to combine LLM-driven textual content summarization right into a scikit-learn Pipeline for knowledge preprocessing.
- Methods to chain summarization, TF-IDF vectorization, and a classifier right into a single end-to-end pipeline.
Textual content Summarization with Scikit-LLM
Picture by Editor
Introduction
In a earlier submit, we launched scikit-LLM, a library that bridges the hole between conventional machine studying fashions and trendy massive language fashions (LLMs). Specifically, we showcased the right way to implement zero-shot and few-shot classification use instances with scikit-LLM.
Now, we try and reply the query: What if our downstream machine studying use case is hampered by huge quantities of textual content? To handle this problem, we’ll discover and use summarizers: one other highly effective characteristic of this library that distills lengthy texts into succinct summaries. Let’s see how, by implementing a knowledge preparation pipeline that includes this course of!
Preliminary Setup
Step one is to be sure to have scikit-LLM put in — change “pip” with “!pip” in case you are working in a cloud pocket book atmosphere:
Notice that by default, scikit-LLM resorts to OpenAI language fashions, which might be costly to run repeatedly, or whose variety of makes use of could also be very restricted underneath a free OpenAI account. Alternatively, you need to use free Hugging Face pre-trained fashions for summarization, like sshleifer/distilbart-cnn-12-6. In such a case, be sure to additionally set up Hugging Face’s Transformers library, to have the ability to load Hugging Face fashions in your program.
|
pip set up transformers==4.37.2 |
LLM-Pushed Textual content Summarization Pipeline
The next class definition encompasses the logic to load a pre-trained mannequin (match()) and apply inference on it, i.e. summarize enter texts (remodel()):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
from sklearn.base import BaseEstimator, TransformerMixin from transformers import pipeline import torch
class HuggingFaceSummarizer(BaseEstimator, TransformerMixin): def __init__(self, model_name=“sshleifer/distilbart-cnn-12-6”, max_length=40, min_length=10): self.model_name = model_name self.max_length = max_length self.min_length = min_length self.summarizer = None self.system = 0 if torch.cuda.is_available() else –1
def match(self, X, y=None): # The match() methodology ought to simply load a pre-trained mannequin into reminiscence # system=0 targets free GPU in case you are utilizing a Colab/Kaggle pocket book. if self.summarizer is None: self.summarizer = pipeline(“summarization”, mannequin=self.model_name, system=self.system) return self
def remodel(self, X): # Guarantee mannequin is loaded if self.summarizer is None: self.summarizer = pipeline(“summarization”, mannequin=self.model_name, system=self.system)
# Course of texts and extract abstract strings outcomes = self.summarizer( X, max_length=self.max_length, min_length=self.min_length, truncation=True ) return [res[‘summary_text’] for res in outcomes] |
Importantly, the category we outlined inherits from customized transformer lessons: a needed step to make sure Hugging Face fashions combine easily with scikit-learn preprocessing and modeling instruments.
For simplicity, say we’ll solely summarize two textual content evaluations which can be half of a bigger dataset for textual content classification. The 2 “lengthy” texts (options) and the evaluations’ sentiments (labels) may seem like:
|
X_long_texts = [ “I’ve been using this vacuum cleaner for about three weeks now. At first, I struggled with the attachments, and the manual wasn’t very clear. However, once I figured out how the motorized brush works, it easily picked up all the pet hair on my rugs. Overall, it’s a solid machine, though a bit heavy to carry up the stairs.”, “The delivery was delayed by four days, which was incredibly frustrating because I needed it for a weekend trip. When the backpack finally arrived, the zipper snagged immediately. I tried to fix it, but the fabric feels cheap and flimsy. I will definitely be returning this and asking for a full refund.”, ]
y_labels = [“positive”, “negative”] |
The actual magic occurs subsequent. We outline a pipeline that brings collectively our knowledge preprocessing — specifically, LLM-driven summarization — and the coaching of a classifier. In an actual state of affairs, you will want excess of two coaching examples to construct a correct classifier, after all, however the level right here is for example how textual content summarization can scale back the dimensionality of textual content knowledge:
|
from sklearn.pipeline import Pipeline from sklearn.feature_extraction.textual content import TfidfVectorizer from sklearn.linear_model import LogisticRegression
# 1. Outline the Pipeline # Naming the variable ‘classification_pipeline’ avoids doable battle with transformers.pipeline operate classification_pipeline = Pipeline([ (‘summarizer’, HuggingFaceSummarizer(max_length=30, min_length=10)), (‘vectorizer’, TfidfVectorizer()), # Used to encode build numerical text representations, needed for ML (‘classifier’, LogisticRegression()) ]) |
As soon as the pipeline has been outlined, right here’s the right way to run it:
|
# 2. Prepare the Pipeline # This downloads the mannequin, summarizes the lengthy texts on the GPU, # vectorizes the quick summaries, and trains a classifier. classification_pipeline.match(X_long_texts, y_labels)
print(“Pipeline educated efficiently on summarized evaluations!”) |
That’s all! Attempt adapting the code above to an actual, labeled textual content dataset for binary sentiment classification, and see the way it works in apply.
Earlier than we wrap up, in case you are interested in what the summarized texts seem like, you possibly can examine the output straight:
|
[” Overall, it’s a solid machine, though a bit heavy to carry up the stairs . At first, I struggled with the attachments,”, ‘ The delivery was delayed by four days, which was incredibly frustrating . The zipper snagged immediately . The fabric feels cheap and flimsy .’] |
The summaries are, after all, removed from the standard you’d get from ChatGPT or Google Gemini — the mannequin we used is a free, light-weight pre-trained mannequin, in any case. That stated, selecting extra highly effective fashions will definitely yield higher outcomes.
Abstract
We bridged the hole between traditional machine studying modeling and superior textual content processing by way of pre-trained massive language fashions, because of scikit-LLM: a library that leverages the most effective of each worlds.
🔥 Need the most effective instruments for AI advertising and marketing? Try GetResponse AI-powered automation to spice up what you are promoting!