🤖 Enhance your productiveness with AI! Discover Quso: all-in-one AI social media suite for good automation.
A deep dive collection on Webex AI Agent
Buyer expectations for AI brokers have essentially modified. A single poor interplay – a sluggish response, an irrelevant reply, a hallucinated coverage – is sufficient to erode belief. In high-volume contact facilities, accuracy, relevance, and velocity are not differentiators – they’re baseline necessities.
Data has all the time been on the coronary heart of nice buyer expertise. Lengthy earlier than AI entered the image, contact middle brokers relied on huge repositories of knowledge – insurance policies, product manuals, procedures, troubleshooting guides – spanning a number of codecs, languages, and techniques. Getting prospects to the best reply, rapidly and precisely, has by no means been easy.
As AI brokers tackle extra of those workflows, the data problem doesn’t simply stay – it scales. They have to repeatedly draw on huge, fragmented, and continually evolving data, retrieving it with precision throughout languages, sustaining context throughout interactions, and surfacing the best reply in real-time – each time.
Counting on a language mannequin’s inner data alone is merely not sufficient – and its a legal responsibility. With out entry to present, enterprise-specific data, AI brokers threat confidently delivering outdated or incorrect solutions, eroding the very belief they’re meant to construct.
Frequent challenges with data retrieval
For this reason retrieval has develop into such a crucial a part of trendy AI techniques. In observe, many AI brokers use Retrieval-Augmented Technology (RAG), which retrieves related data from trusted enterprise sources and makes use of it to floor the mannequin’s response.
Whereas the idea is easy, delivering it successfully in enterprise environments is much extra complicated.
In enterprise environments, data retrieval is troublesome for a variety of causes:
- Content material lives in different doc codecs and techniques
- Necessary data is usually embedded in complicated layouts, together with tables, charts, and pictures
- Data should be retrieved precisely throughout languages
- Lack of context resulting from simplistic chunking methods
- Vector search alone can miss crucial outcomes or return loosely associated content material
- Consumer queries are sometimes conversational, ambiguous, or incomplete
- Latency constraints in real-time environments like contact facilities
These obstacles can sluggish the creation of AI-friendly data repositories, hindering adoption and limiting the effectiveness of AI Brokers.
Webex’s strategy
At Webex, we’ve reimagined RAG from the bottom as much as tackle these real-world enterprise challenges. Our AI Agent RAG structure combines superior doc processing, adaptive multilingual intelligence, hybrid retrieval, and low-latency optimization to ship exact, context-rich solutions at scale.
Beneath, we break down every of those improvements, the engineering choices behind them, and the affect they ship in real-world manufacturing environments.
Remodeling enterprise paperwork into LLM-ready data
Fashionable enterprises retailer data throughout various codecs — PDFs, spreadsheets, Phrase paperwork, slide decks — that not often comply with clear constructions. These paperwork typically include complicated layouts with pictures, tables, charts, multi-column formatting, and nested sections. For an AI Agent to ship dependable solutions, it should course of this content material with out dropping which means or context.
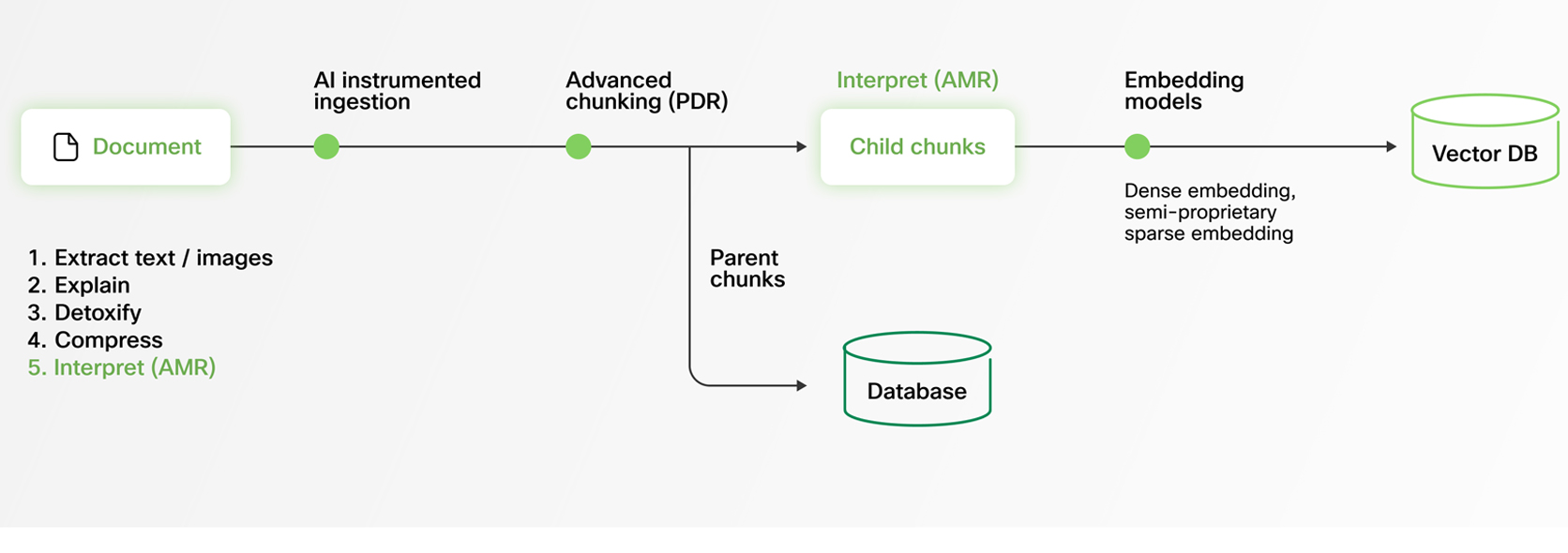
At Webex, we’ve engineered our AI Agent RAG pipeline to embrace this actuality. Our system ingests various doc codecs and extracts structured data from even probably the most complicated information.
To make this content material LLM-friendly, we convert every part into Markdown, a flexible and extensively adopted format for structured textual content. This transformation is non-trivial: parsing graphics, preserving desk information, and sustaining contextual relationships between parts all require subtle processing. Our superior doc pipeline ensures that crucial data isn’t misplaced in translation, empowering AI Brokers to generate exact, complete, and contextually correct responses.
Multilingual by design
For international enterprises, data doesn’t exist in only one language. Product documentation and assist content material are created and maintained throughout a number of areas — typically in a number of languages. But many RAG techniques battle with multilingual content material, resulting in inconsistent retrieval high quality, decreased accuracy, and uneven buyer experiences.
The underlying problem is refined however important: whereas multilingual embedding and re-ranking fashions have made spectacular progress, they nonetheless obtain their highest accuracy in English. Strong fashions for different languages are bettering, however efficiency gaps stay — particularly in high-precision retrieval eventualities.
Our AI Agent RAG system is architected from the bottom as much as remedy this by Adaptive Monolingual RAG (AMR).
Whatever the supply doc’s language, our system normalizes content material to English internally for retrieval and reranking. This allows us to leverage the world’s most superior English-trained fashions — delivering industry-leading accuracy, even when the unique paperwork are in different languages.
The result’s consistency, precision, and reliability throughout each deployment, for each buyer, in each language.
Context preservation by mother or father–baby chunking
Retrieving the best data in RAG isn’t nearly relevance — it’s about context. If too little content material is retrieved, the AI Agent could miss crucial particulars. If an excessive amount of is retrieved, the mannequin may be overwhelmed with irrelevant data. Hanging the best steadiness between precision and completeness is without doubt one of the most persistent challenges in manufacturing RAG techniques.
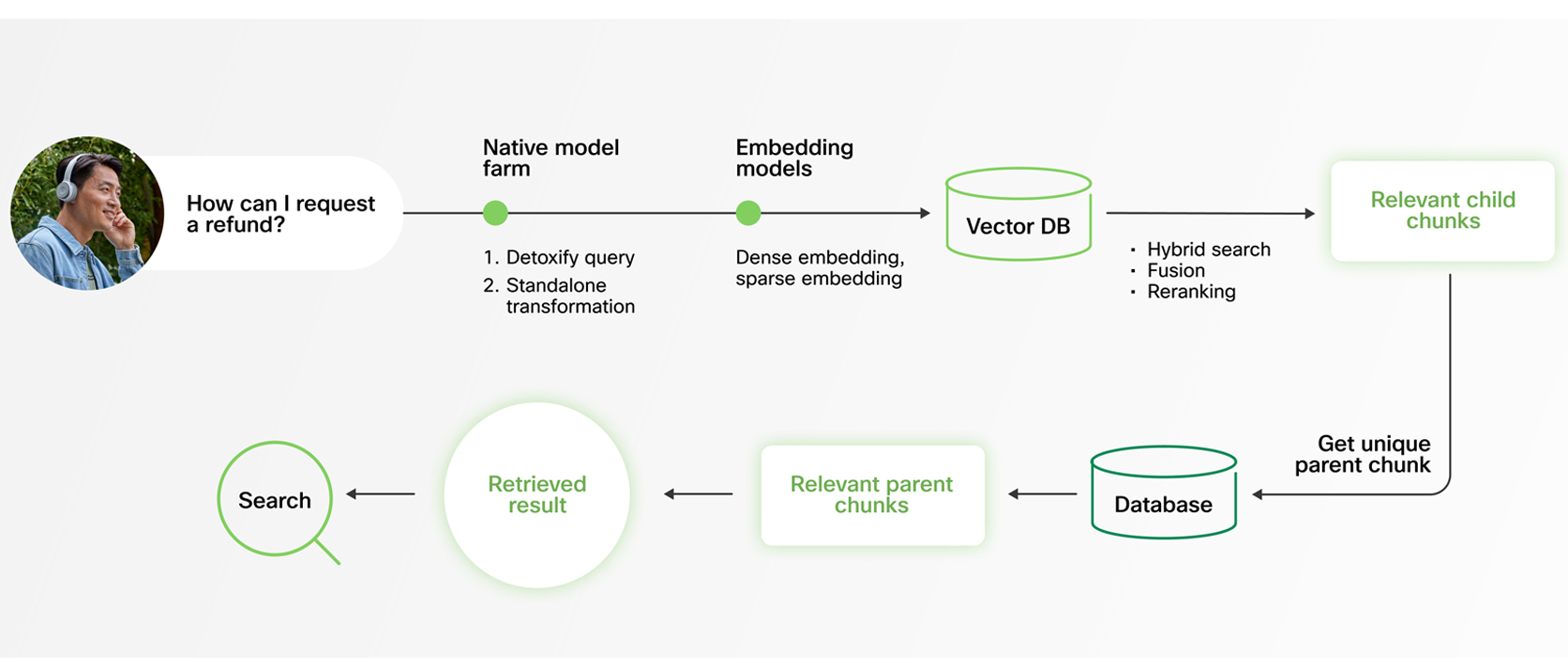
Webex AI Agent addresses this with a hierarchical Dad or mum–Youngster Chunking technique (also referred to as Dad or mum Doc Retrieval).
Throughout retrieval, the system searches throughout smaller, finely tuned baby chunks. This allows quick, exact, and extremely granular matching. As soon as related sections are recognized, responses are generated utilizing their corresponding mother or father chunks — bigger sections of the doc that present broader context and extra full data.
This dual-level strategy ensures that solutions usually are not solely correct, but additionally context-rich and coherent. Quite than being constrained by arbitrary chunk boundaries, the mannequin advantages from each precision in retrieval and depth in response era. Mixed with trendy LLMs’ expanded context home windows, this technique ensures absolutely knowledgeable, coherent responses.
Understanding smarter retrieval by hybrid search
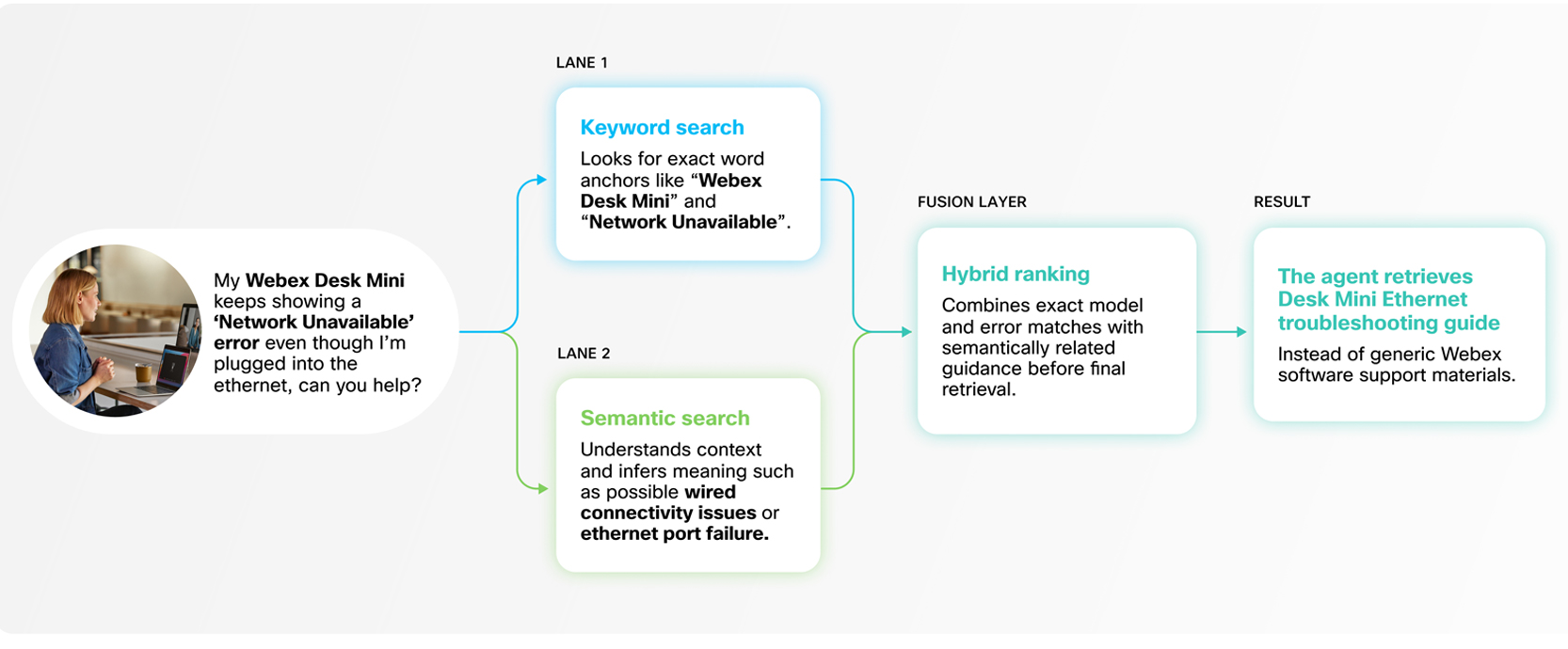
Counting on a single retrieval technique can restrict accuracy. Pure vector (semantic) search is highly effective for understanding intent and which means, however it may well miss actual matches — particularly when queries embrace technical jargon, product codes, or direct quotations. However, key phrase search is extremely exact however lacks semantic depth. In manufacturing environments, neither strategy alone is enough.
Webex AI Agent addresses this with a hybrid search technique that mixes each.
Our RAG system integrates key phrase and vector search utilizing weight-based balancing, adopted by entailment-controlled reranking to refine outcomes. This ensures that actual matches are captured when mandatory, whereas nonetheless preserving the contextual understanding required for nuanced queries.
The result is complete, high-precision retrieval with out added latency. Prospects profit from the most effective of each approaches — quick, correct, and contextually related solutions, each time.
Retrieving primarily based on intent, not simply enter
Buyer queries in real-world conversations are not often full or self-contained. They’re typically brief, ambiguous, or depending on prior context. When a buyer responds with one thing like “Sure” to “Do you want extra data?”, the intent can solely be understood by referencing the previous dialogue. By itself, “Sure” is meaningless to a retrieval system.
To deal with this, Webex AI Agent features a purpose-built, light-weight question reframing mannequin. This mannequin reconstructs full, context-rich queries from conversational fragments earlier than retrieval happens.
Rigorously examined for each excessive accuracy and ultra-low latency, this strategy ensures that our RAG system retrieves data primarily based on true intent — not simply surface-level inputs. The result’s extra related solutions, smoother interactions, and constantly higher buyer experiences.
Constructed for real-time efficiency
Involved facilities, each millisecond counts. Excessive-volume buyer interactions demand AI Brokers that ship correct solutions immediately, retaining conversations seamless and buyer experiences frictionless. On this setting, low-latency RAG isn’t only a technical optimization — it’s a enterprise requirement.
Webex AI Agent’s RAG system is engineered for real-time efficiency with out sacrificing precision or depth. Our improvements in language-agnostic data processing, adaptive multilingual retrieval, hierarchical chunking, hybrid search, reranking, and standalone question era usually are not remoted options — they work collectively as a unified structure optimized for velocity and reliability.
By fixing the toughest challenges in data ingestion, multilingual accuracy, context preservation, and conversational intent, Webex AI Agent units a brand new commonplace for AI-powered buyer engagement — delivering constant, exact, and responsive experiences at scale.
🚀 Stage up your duties with GetResponse AI-powered instruments to streamline your workflow!
{kind=link}