🤖 Increase your productiveness with AI! Discover Quso: all-in-one AI social media suite for good automation.
A deep dive sequence on Webex AI Agent
This blogpost is devoted to the reminiscence of Jay Patel, an enthusiastic champion of our AI Agent imaginative and prescient and a tireless advocate for each millisecond of enchancment.
Why low latency issues for voice AI
In voice AI, latency is every thing. People naturally pause for only some hundred milliseconds between talking turns — so when an AI agent waits longer, the dialog instantly feels robotic and inattentive. For AI brokers, staying inside that pure pause window is vital as a result of even small delays can break the circulate and frustrate prospects.
On telephony community (PSTN) the problem is even harder, as roughly 500 ms of latency is launched throughout the decision path – leaving only some hundred milliseconds for flip detection, retrieval, reasoning and speech synthesis. Effectivity in each element is important to maintain conversations flowing naturally.
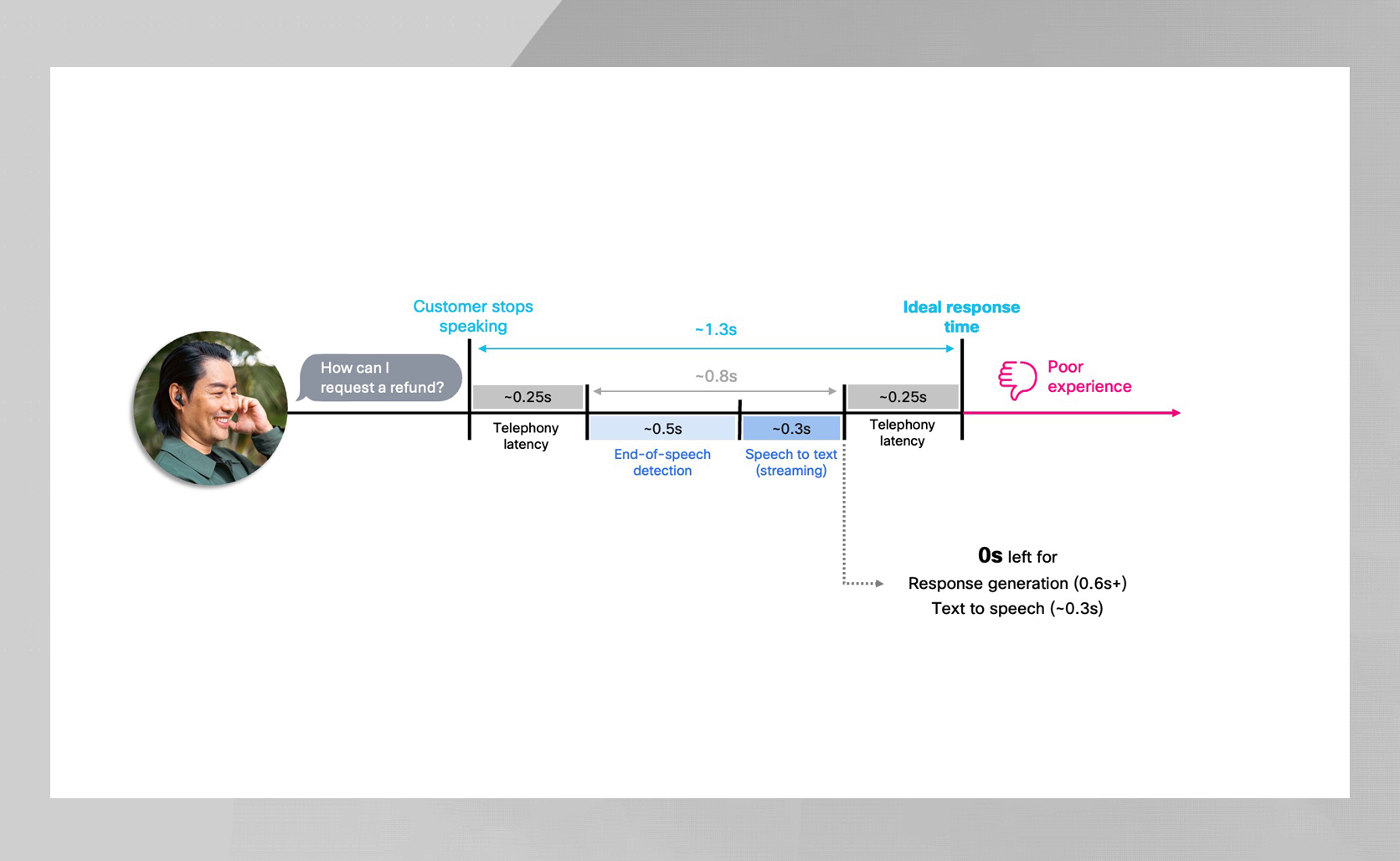
But velocity alone isn’t sufficient. Smaller fashions could also be quick, however actual customer-facing brokers should even be correct, instruction-following, hallucination-resistant, and enterprise-grade — qualities tiny fashions merely don’t ship. Bigger fashions present that intelligence, however at the price of added latency. And that latency issues most as soon as you progress past internet demos and into actual calls. Delivering velocity is straightforward in internet demos, the place connections are larger constancy and keep away from the PSTN’s additional latency and encoding overhead. The actual problem is delivering that intelligence whereas nonetheless responding in underneath a second on actual telephony paths.
That is the place Cisco takes a singular strategy. By combining the intelligence of high-quality fashions with deep latency engineering, Webex AI Agent delivers responses which can be good, rapid, and really feel human.
Our strategy
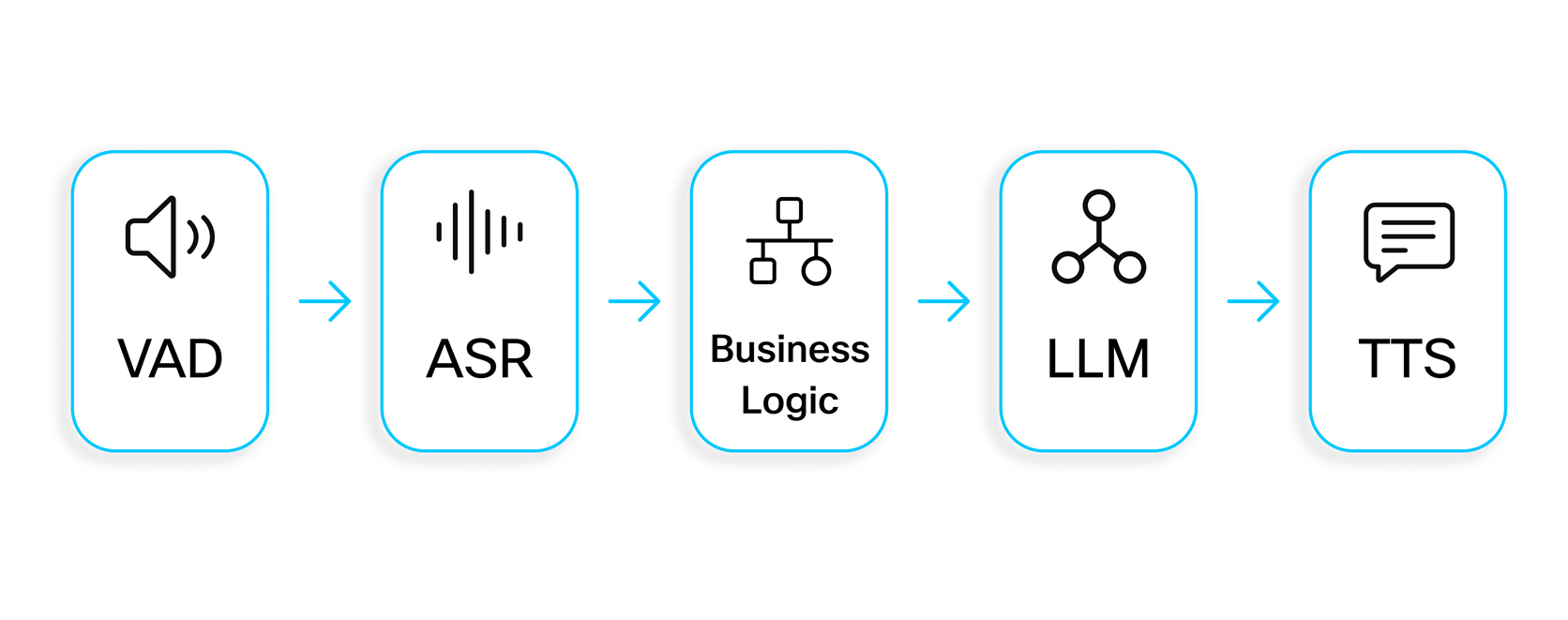
To ship pure, low-latency responses, we use a modular pipeline: Voice Exercise Detection (VAD) → Computerized Speech Recognition (ASR) → enterprise logic → Massive Language Mannequin (LLM) → Textual content-to-Speech (TTS). This construction supplies transparency and permits every element to be tuned for each velocity and high quality.
VAD detects when the client begins and stops talking, enabling barge-in and switch taking, whereas ASR converts speech to textual content, a vital step since all downstream logic depends on its accuracy. The enterprise logic layer then interprets the transcript, managing flip detection (with entity-aware checks like digit sequences), grounding LLM responses with retrieval-augmented era (RAG), which fetches related details from company information bases to stop hallucinations, and dealing with extra selections resembling small-talk detection and gear utilization.
The LLM generates the reply utilizing transcript, context, and retrieved knowledge, and TTS produces the pure audio the client hears. We presently deploy trillion-parameter business fashions alongside Cisco’s inside fashions to stability accuracy and latency, as detailed in our Webex AI Transparency Notice. VAD and switch detection guarantee we all know exactly when to talk, RAG and enterprise logic floor the solutions, and the LLM and TTS ship high-quality responses – all inside strict timing constraints. Behind the scenes, a number of proprietary Cisco fashions present extra intelligence and latency optimizations, additional enhancing accuracy and responsiveness.
These decisions will proceed to evolve because the business and mannequin capabilities advance.
Producing the primary a part of the ultimate reply upfront
A key optimization is producing the start of the ultimate reply whereas the client remains to be talking. As a substitute of ready for a full transcript and accomplished retrievals, we pre-compute an preliminary phase in order that playback can begin instantly as soon as VAD and TD verify the tip of flip. This mirrors human dialog: expert brokers start talking as they’re nonetheless formulating the remainder of their response. By producing the primary half early, we preserve sub-second responsiveness whereas heavier, extra correct fashions proceed processing within the background.
Why This Issues
With out upfront era, we’d be compelled to make use of a lot smaller, much less correct fashions to fulfill latency budgets. Meaning actual tradeoffs: the LLM would have to be light-weight with weaker instruction following, the ASR might need to be ultra-fast however much less correct, and the TTS would seemingly depend on sooner however robotic-sounding engines. In apply, prospects would get responses sooner, however these responses could be noticeably much less useful, pure, and reliable.
By producing and caching the primary half early, we create invaluable time for slower, higher-quality reasoning, retrieval, and synthesis. That respiration room lets bigger, extra succesful fashions run within the background to carry out the heavier reasoning and retrieval wanted to generate clever responses – all earlier than the client ever notices a delay. The result’s velocity with out compromise, fast responses which can be each correct and pure.
Challenges and Design Decisions
Producing early output introduces a number of necessities:
- Incomplete enter: The early phase should be secure, contextually believable, and capable of proceed naturally after the complete reasoning completes.
- Continuation mannequin: We by no means discard the early half; the ultimate reply merely continues from it.
- Mid-sentence flexibility: The early half doesn’t have to be a full sentence (e.g., “I’m completely happy to assist…”), making it mix seamlessly into the ultimate reply.
- A number of candidates: We generate a number of potential begins and decide one of the best one as extra context arrives.
This design delivers a single, clean response from the client’s perspective, at the same time as advanced processing continues behind the scenes.

Further latency optimizations
Throughout the stack, we implement a number of engineering optimizations, every shaving small quantities of time to maintain the pipeline quick even when utilizing higher-quality fashions.
Streaming
- Low-latency ASR/TTS streaming
- LLM token streaming
Infrastructure
- Regional media colocation
- Reserved capability for vital LLM calls
Modelling
- Hybrid multi-model mixtures for light-weight duties
- Sturdy Finish of Speech (EOS) detection combining VAD, ASR, and customized indicators
Caching
- Frequent immediate caching
- Pre-synthesized audio
On the infrastructure aspect, we construct a number of layers of resilience to maintain latencies predictable underneath actual manufacturing situations. This contains an LLM proxy with regional failover, parallel “safety-net” requests to hedge towards sluggish LLM responses, coordinated retries and caching for ASR and TTS paths, and a system-wide orchestration layer that dynamically adjusts mannequin sizes and fallback methods.
Actual life latency numbers
We measure latency from the second the client stops chatting with once they hear the primary audio. In apply, the breakdown appears to be like like this:
- VAD EOS: ~500 ms
- Flip Detection: <75 ms p99
- First a part of reply: Already generated + cached by EOS
- TTS for the primary phase: Normally 10–20 ms (resulting from cache hits)
- PSTN return path: ~500 ms
As a result of the early phase is prepared instantly at EOS, playback can begin virtually immediately. In the meantime, the heavier era and RAG retrieval full in parallel, seamlessly persevering with the reply. The result’s pure, sub-second responsiveness regardless of bigger fashions working within the background.
Our low latency benefit
Delivering a very human, pure, and rapid voice AI expertise requires greater than connecting ASR, LLM, and TTS. It calls for cautious orchestration of each element — precision flip detection, early-answer era, caching, and resilient infrastructure — all working collectively to attenuate latency with out compromising intelligence.
Webex AI Agent combines high-quality fashions with deep latency engineering to persistently obtain ~1.3 second PSTN latencies over actual telephony paths. The result’s an AI agent that feels human, attentive, and dependable, serving to enterprises meet buyer expectations whereas sustaining accuracy, grounding, and enterprise-grade reliability.
Uncover how Webex AI Agent can convey quick, pure, and correct voice experiences to your PSTN interactions — attain out to your Webex gross sales consultant or associate for a personalised demo.
🚀 Stage up your duties with GetResponse AI-powered instruments to streamline your workflow!
{kind=link}