On this article, we’ll discuss classical computation: the form of computation usually present in an undergraduate Laptop Science course on Algorithms and Knowledge Constructions [1]. Suppose shortest path-finding, sorting, intelligent methods to interrupt issues down into less complicated issues, unbelievable methods to organise knowledge for environment friendly retrieval and updates. In fact, given The Gradient’s deal with Synthetic Intelligence, we won’t cease there; we can even examine how one can seize such computation with deep neural networks.
Why seize classical computation?
Perhaps it’s price beginning by clarifying the place my vested curiosity in classical computation comes from. Aggressive programming—the artwork of fixing issues by quickly writing packages that have to terminate in a given period of time, and inside sure reminiscence constraints—was a extremely fashionable exercise in my secondary college. For me, it was actually the gateway into Laptop Science, and I belief the story is comparable for a lot of machine studying practitioners and researchers at present. I’ve been capable of win a number of medals at worldwide programming competitions, such because the Northwestern Europe Regionals of the ACM-ICPC, the top-tier Laptop Science competitors for college college students. Hopefully, my successes in aggressive programming additionally give me some credentials to put in writing about this matter.
Whereas this could clarify why I care about classical computation, why ought to all of us care? To reach at this reply, allow us to ponder among the key properties that classical algorithms have:
- They’re provably appropriate, and we will usually have robust ensures concerning the assets (time or reminiscence) required for the computation to terminate.
- They provide robust generalisation: whereas algorithms are sometimes devised by observing a number of small-scale instance inputs, as soon as applied, they are going to work with out fault on inputs which can be considerably bigger, or distributionally totally different than such examples.
- By design, they’re interpretable and compositional: their (pseudo)code illustration makes it a lot simpler to purpose about what the computation is definitely doing, and one can simply recompose varied computations collectively by means of subroutines to realize totally different capabilities.
Taking a look at all of those properties taken collectively, they appear to be precisely the problems that plague fashionable deep neural networks essentially the most: you may hardly ever assure their accuracy, they usually collapse on out-of-distribution inputs, and they’re very infamous as black packing containers, with compounding errors that may hinder compositionality.
Nonetheless, it’s precisely these expertise which can be essential for making AI instructive and helpful to people! For instance, to have an AI system that reliably and instructively teaches an idea to a human, the standard of its output shouldn’t rely upon minor particulars of the enter, and it ought to be capable to generalise that idea to novel conditions. Arguably, these expertise are additionally a lacking key step on the street to constructing generally-intelligent brokers. Subsequently, if we’re capable of make any strides in direction of capturing traits of classical computation in deep neural networks, that is more likely to be a really fruitful pursuit.
First impressions: Algorithmic alignment
My journey into the sector began with an attention-grabbing, however seemingly inconsequential query:
Can neural networks be taught to execute classical algorithms?
This may be seen as a great way to benchmark to what extent are sure neural networks able to behaving algorithmically; arguably, if a system can produce the outputs of a sure computation, it has “captured” it. Additional, studying to execute gives a uniquely well-built surroundings for evaluating machine studying fashions:
- An infinite knowledge supply—as we will generate arbitrary quantities of inputs;
- They require complicated knowledge manipulation—making it a difficult activity for deep studying;
- They’ve a clearly specified goal perform—simplifying interpretability analyses.
Once we began learning this space in 2019, we actually didn’t suppose extra of it than a really neat benchmark—nevertheless it was definitely turning into a really vigorous space. Concurrently with our efforts, a workforce from MIT tried tackling a extra formidable, however strongly associated drawback:
What makes a neural community higher (or worse) at becoming sure (algorithmic) duties?
The landmark paper, “What Can Neural Networks Purpose About?” [2] established a mathematical basis for why an structure could be higher for a activity (when it comes to pattern complexity: the variety of coaching examples wanted to scale back validation loss under epsilon). The authors’ primary theorem states that higher algorithmic alignment results in higher generalisation. Rigorously defining algorithmic alignment is out of scope of this textual content, however it may be very intuitively visualised:
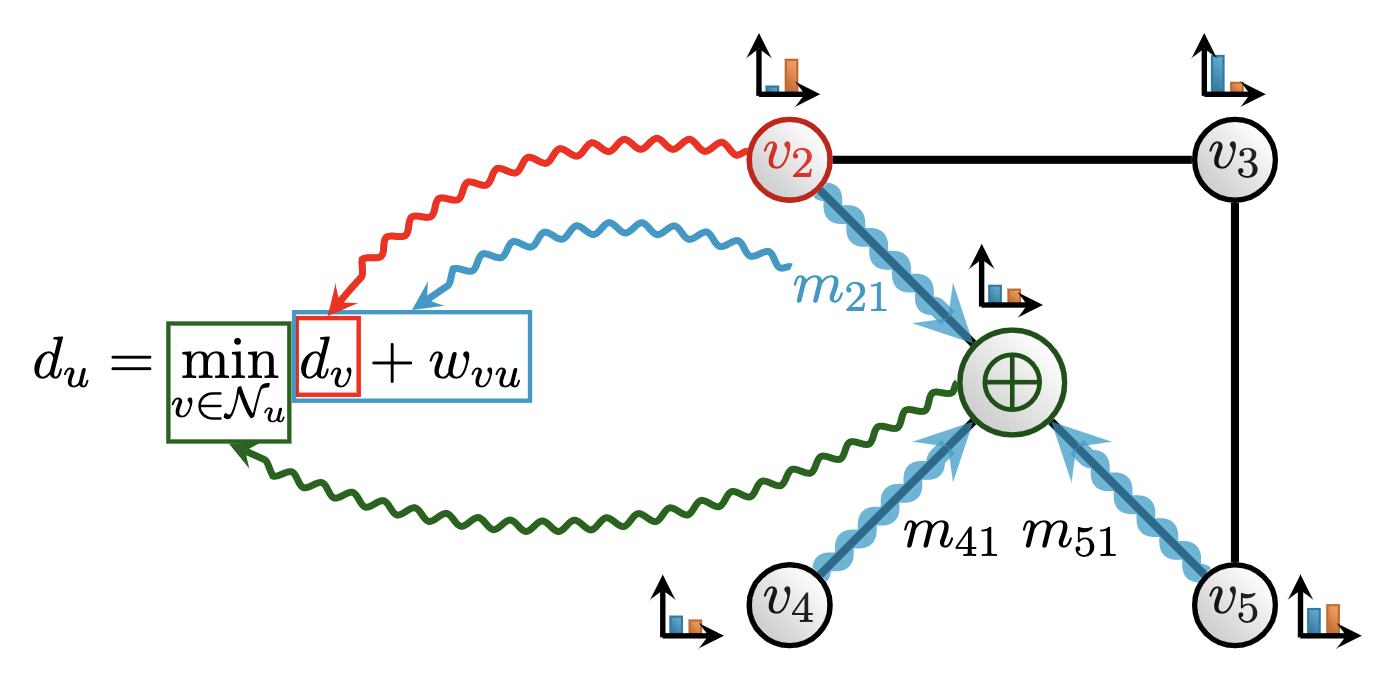
Right here, we will see a visible decomposition of how a graph neural community (GNN) [3] aligns with the classical Bellman-Ford [4] algorithm for shortest path-finding. Particularly, Bellman-Ford maintains its present estimate of how distant every node is from the supply node: a distance variable (du) for every node u in a graph. At each step, for each neighbour v of node u, an replace to du is proposed: a mixture of (optimally) reaching v, after which traversing the sting connecting v and u (du + wvu). The space variable is then up to date because the optimum out of all of the proposals. Operations of a graph neural community can naturally decompose to comply with the info stream of Bellman-Ford:
- The space variables correspond to the node options maintained by the GNN;
- Including the sting distance to a distance variable corresponds to computing the GNN’s message perform;
- Selecting the optimum neighbour based mostly on this measure corresponds to the GNN’s permutation-invariant aggregation perform, ⨁.
Usually, it may be confirmed that, the extra carefully we will decompose our neural community to comply with the algorithm’s construction, the extra beneficial pattern complexity we will anticipate when studying to execute such algorithms. Bellman-Ford is a typical occasion of a dynamic programming (DP) algorithm [5], a general-purpose problem-solving technique that breaks the issue down into subproblems, after which recombines their options to seek out the ultimate answer.
The MIT workforce made the essential statement that GNNs seem to algorithmically align with DP, and since DP can itself be used to precise many helpful types of classical computation, GNNs needs to be a really potent general-purpose mannequin for studying to execute. This was validated by a number of fastidiously constructed DP execution benchmarks, the place relational fashions like GNNs clearly outperformed architectures with weaker inductive biases. GNNs have been a long-standing curiosity of mine [6], so the time was proper to launch our personal contribution to the world:
Neural Execution of Graph Algorithms
On this paper [7], concurrently launched with Xu et al. [2], we performed a radical empirical evaluation of studying to execute with GNNs. We discovered that whereas algorithmic alignment is certainly a robust software for mannequin class choice, it sadly doesn’t permit us to be reckless. Particularly, we can not simply apply any expressive GNN to an algorithmic execution activity and anticipate nice outcomes, particularly out-of-distribution—which we beforehand recognized as a key setting by which “true” reasoning programs ought to carry out nicely. Very like different neural networks, GNNs can very simply overfit to the traits of the distribution of coaching inputs, studying “intelligent hacks” and sidestepping the precise process that they’re making an attempt to execute.
We therefore determine three key observations on cautious inductive biases to make use of, to enhance the algorithmic alignment to sure path-finding issues even additional and permit for generalising to 5x bigger inputs at check time:
- Most conventional deep studying setups contain a stack of layers with unshared parameters. This basically limits the quantity of computation the neural community can carry out: if, at check time, an enter a lot bigger than those within the coaching knowledge arrives, it could be anticipated that extra computational steps are wanted—but, the unshared GNN has no approach to help that. To handle this, we undertake the encode-process-decode paradigm [8]: a single shared processor GNN is iterated for a lot of steps, and this variety of steps will be variable at each coaching and inference time. Such an structure additionally permits a neat approach to algorithmically align to iterative computation, as most algorithms contain repeatedly making use of a sure computation till convergence.
- Since most path-finding algorithms (together with Bellman-Ford) require “native” optimisation (i.e. selecting precisely one optimum neighbour at each step), we opted to make use of max aggregation to mix the messages despatched in GNNs. Whereas this may occasionally look like a really intuitive concept, it went strongly towards the folklore of the occasions, as max-GNNs had been recognized to be theoretically inferior to sum-GNNs at distinguishing non-isomorphic graphs [9]. (We now have stable theoretical proof [10] for why it is a good concept.)
- Lastly, whereas most deep studying setups solely require producing an output given an enter, we discovered that this misses out on a wealth of how to instruct the mannequin to align to the algorithm. For instance, there are various attention-grabbing invariants that algorithms have that may be explicitly taught to a GNN. Within the case of Bellman-Ford, after okay iterations are executed, we needs to be anticipated to have the ability to recuperate all shortest paths which can be not more than okay hops away from the supply node. Accordingly, we use this perception to offer step-wise supervision to the GNN at each step. This concept seems to be gaining traction in Massive Language Mannequin design in latest months [11, 12].
All three of the above modifications make for stronger algorithmically-aligned GNNs.
Enjoying the alignment recreation
It should be harassed that the intuitive concept of algorithmic alignment—taking inspiration from Laptop Science ideas in structure design—is under no circumstances novel! The text-book instance of this are the neural Turing machine (NTM) and differentiable neural laptop (DNC) [13, 14]. These works are decisively influential; actually, in its try to make random-access reminiscence suitable with gradient-based optimisation, the NTM gave us one of many earliest types of content-based consideration, three years earlier than Transformers [15]!
Nonetheless, regardless of their affect, these architectures are these days just about by no means utilized in apply. There are lots of potential causes for this, however in my view it’s as a result of their design was too brittle: making an attempt to introduce many differentiable parts into the identical structure without delay, with out a clear steerage on how to compose them, or a approach to simply debug them as soon as they failed to point out helpful sign on a brand new activity. Our line of labor nonetheless desires to construct one thing like an NTM—however make it extra efficiently deployed, by utilizing algorithmic alignment to extra fastidiously prototype every constructing block in isolation, and have a extra granular view of which blocks profit execution of which goal algorithms.
Our strategy of “taking part in the algorithmic alignment recreation” seems to have yielded a profitable line of specialized (G)NNs, and we now have worthy ‘fine-grained’ options for studying to execute linearithmic sequence algorithms [16], iterative algorithms [17], pointer-based knowledge buildings [18], in addition to persistent auxiliary reminiscence [19]. Finally, these insights additionally carried over to extra fine-grained concept as nicely. In gentle of our NEGA paper [7], the inventors of algorithmic alignment refined their concept into what’s now often known as linear algorithmic alignment [10], offering justification for, amongst different issues, our use of the max aggregation. More moderen insights present that understanding algorithmic alignment might require causal reasoning [20,21], correctly formalising it might require class concept [22], and correctly describing it might require analysing asynchronous computation [23]. Algorithmic alignment is due to this fact turning into a really thrilling space for mathematical approaches to deep studying in recent times.
Why not simply run the goal algorithm?…and rebuttals
Whereas it seems lots of helpful progress has been made in direction of addressing our preliminary “toy query”, the concept of studying to execute shouldn’t be one which simply passes peer overview. My private favorite reviewer remark I obtained—quoted in full—was as follows: “This paper will definitely speed up analysis in constructing algorithmic fashions, and there’s definitely lots of researchers that might make benefit of it, I’m simply undecided that this analysis ought to even exist”.
That is clearly not the nicest factor to obtain as the primary creator of a paper. However nonetheless, let’s attempt to put my ego apart, and see what will be taken away from such opinions. There’s a clear sense by which such opinions are elevating a completely legitimate level: tautologically, the goal algorithm will execute itself higher (or equally good) than any GNN we’d ever be taught over it. Clearly, if we wish wide-spread recognition of those concepts, we have to present how studying to execute will be usefully utilized past the context of “pure” execution.
Our exploration led us to many potential concepts, and within the the rest of this text, I’ll present three concepts that noticed essentially the most impression.
First, algorithmically aligned fashions can speed up science. And if you need clear proof of this, look no additional than the quilt of Nature [24]. In our work, we practice (G)NNs to suit a mathematical dataset of curiosity to a mathematician, after which use easy gradient saliency strategies to sign to the mathematician which components of the inputs to focus their consideration at. Whereas such indicators are sometimes remarkably noisy, they do permit a mathematician to check solely essentially the most salient 20-30 nodes in a graph that might in any other case have lots of or hundreds of nodes, making sample discovery a lot simpler. The found patterns can then type the idea of novel theorems, and/or be used to derive conjectures.
With this straightforward strategy, we had been capable of drive impartial contributions to 2 extremely disparate areas of math: knot concept [25] and illustration concept [26], each subsequently printed of their areas’ respective top-tier journals, therefore incomes us the Nature accolade. However, whereas our strategy is easy in precept, a query arose particularly within the illustration concept department: which (G)NN to make use of? Normal expressive GNNs didn’t yield clearly interpretable outcomes.
That is the place algorithmic alignment helped us: Geordie Williamson, our illustration concept collaborator, offered an algorithm that might compute the outputs we care about, if we had entry to privileged info. We achieved our greatest outcomes with a GNN mannequin that was explicitly aligning its parts to this goal algorithm.
Extra typically: on this case, a goal algorithm existed, however executing it was inapplicable (as a result of privileged inputs). Algorithmic alignment allowed us to embed “priors” from it anyway.
Second, algorithmically aligned fashions are quick heuristics. In latest work with laptop networking and machine studying collaborators from ETH Zürich, we studied the applicability of neural algorithmic reasoning in laptop networking [27]. Particularly, we sought to expedite the difficult activity of configuration synthesis: based mostly on a given specification of constraints a pc community ought to fulfill, produce a corresponding community configuration (a graph specifying the routers in a community and their connections). This configuration should fulfill the entire specs, as soon as a community protocol has been executed over it.
Producing these configurations is understood to be a really difficult NP-hard drawback—in apply, it’s often solved with sluggish SMT solvers, which may usually require doubly-exponential complexity. As a substitute, we select to make use of concepts from algorithmic reasoning to generate configurations by inverting the protocol (which will be seen as a graph algorithm). Particularly, we generate many random community configurations, execute the protocol over them, and acquire all true information concerning the ensuing community to extract corresponding specs. This offers us all we have to generate a graph-based dataset from specs to configurations, and match an algorithmically-aligned GNN to this dataset.
Naturally, by advantage of simply requiring a ahead go of a machine studying mannequin, this strategy is considerably quicker than SMT solvers at inference time: for sure configurations, we have now noticed over 490x speedup over the prior state-of-the-art. In fact, there is no such thing as a free lunch: the worth we pay for this speedup are occasional inaccuracies within the produced configurations at test-time. That being mentioned, on all of the related distributions we evaluated, the common variety of constraints glad has constantly been over 90%, which makes our technique already relevant for downstream human-in-the-loop use—and it’s more likely to speed up human designers, as fairly often, the preliminary configurations are unsatisfiable, that means SMT solvers will spend lots of effort solely to say a satisfying configuration can’t be discovered. Throughout this time, a quick ahead go of a GNN may have allowed for a lot extra speedy iteration.
Extra typically: on this case, a goal algorithm is simply being approximated, however such that it gives a quick and moderately correct heuristic, enabling speedy human-in-the-loop iteration.
A core drawback with making use of classical algorithms
To set us up for the third and remaining concept, let me pose a motivating activity: “Discover me the optimum path from A to B”. How do you reply to this immediate?
Chances are high, particularly in case you come from a theoretical Laptop Science background like me, that you’ll reply to this query in a really singular method. Particularly, you’ll subtly assume that I’m offering you with a weighted graph and asking you for the shortest path between two particular vertices on this graph. We will then diligently apply our favorite path-finding algorithm (e.g. Dijkstra’s algorithm [28]) to resolve this question. I ought to spotlight that, not less than on the time of penning this textual content, the scenario shouldn’t be very totally different with most of at present’s state-of-the-art AI chatbots—when prompted with the above activity, whereas they are going to usually search additional info, they are going to promptly assume that there’s an enter weighted graph offered!
Nonetheless, there’s nothing in my query that requires both of those assumptions to be true. Firstly, the real-world is usually extremely noisy and dynamic, and infrequently gives such abstractified inputs. For instance, the duty may concern the optimum approach to journey between two locations in a real-world transportation community, which is a difficult routing drawback that depends on processing noisy, complicated knowledge to estimate real-time visitors speeds—a lesson I’ve personally learnt, once I labored on deploying GNNs inside Google Maps [29]. Secondly, why should “optimum” equal shortest? Within the context of routing visitors, and relying on the precise contexts and objectives, “optimum” might nicely imply most cost-efficient, least polluting, and so forth. All of those variations make an easy software of Dijkstra’s algorithm troublesome, and will in apply require a mixture of a number of algorithms.
Each of those points spotlight that we regularly have to make a difficult mapping between complicated real-world knowledge and an enter that will likely be acceptable for working a goal algorithm. Traditionally, this mapping is carried out by people, both manually or by way of specialised heuristics. This naturally invitations the next query: Can people ever hope to have the ability to manually discover the required mapping, typically? I’d argue that, not less than because the Fifties, we’ve recognized the reply to this query to be no. Immediately quoting from the paper of Harris and Ross [30], which is likely one of the first accounts of the most stream drawback (by means of analysing railway networks):
The analysis of each railway system and particular person observe capacities is, to a substantial extent, an artwork. The authors know of no examined mathematical mannequin or components that features all variations and imponderables that should be weighed. Even when the person has been carefully related to the actual territory he’s evaluating, the ultimate reply, nonetheless correct, is basically one in every of judgment and expertise.
Therefore, even extremely expert people usually have to make educated guesses when attaching a single scalar “capability” worth to every railway hyperlink—and this must be performed earlier than any stream algorithm will be executed over the enter community! Moreover, as evidenced by the next assertion from the latest Amazon Final Mile Routing Analysis Problem [31],
…there stays an essential hole between theoretical route planning and real-life route execution that the majority optimization-based approaches can not bridge. This hole pertains to the truth that in real-life operations, the standard of a route shouldn’t be completely outlined by its theoretical size, length, or price however by a large number of things that have an effect on the extent to which drivers can successfully, safely, and conveniently execute the deliberate route below real-life circumstances.
Therefore, these issues stay related even within the high-stakes, massive knowledge settings of at present. This can be a elementary divide between classical algorithms and the real-world issues they had been initially designed to unravel! Satisfying the strict preconditions for making use of an algorithm might result in drastic lack of info from complicated, naturally-occurring inputs. Or, put merely:
It doesn’t matter if the algorithm is provably appropriate, if we execute it on the unsuitable inputs!
This difficulty will get considerably tricker if the info is partially observable, there are adversarial actors within the surroundings, and so forth. I need to stress that this isn’t a difficulty theoretical laptop scientists are inclined to concern themselves with, and doubtless for good purpose! Focussing on the algorithms within the “abstractified” setting is already fairly difficult, and it has yielded among the most lovely computational routines which have considerably reworked our lives. That being mentioned, if we need to give “superpowers” to those routines and make them relevant method past the sorts of inputs they had been initially envisioned for, we have to discover some approach to bridge this divide. Our proposal, the neural algorithmic reasoning blueprint [32], goals to bridge this divide by neuralising the goal algorithm.
Neural Algorithmic Reasoning
Since a key limitation we recognized is the necessity for handbook enter characteristic engineering, an excellent first level of assault could possibly be to easily change the characteristic engineer with a neural community encoder. In spite of everything, changing characteristic engineering is how deep studying bought its main breakthrough [33]! The encoder would be taught to foretell the inputs to the algorithm from the uncooked knowledge, after which we will execute the algorithm over these inputs to acquire the outputs we care about.
This sort of pipeline is remarkably fashionable [34]; in latest occasions, there have been seminal outcomes permitting for backpropagating by means of the encoder even when the algorithm itself is non-differentiable [35]. Nonetheless, it suffers from an algorithmic bottleneck drawback: particularly, it’s absolutely committing itself to the algorithm’s outputs [36]. That’s, if the inputs to the algorithm are poorly predicted by the encoder, we run into the identical difficulty as earlier than—the algorithm will give an ideal reply in an incorrect surroundings. For the reason that required inputs are often scalar in nature (e.g. a single distance per fringe of the enter graph), the encoder is usually tasked with mapping the extraordinarily wealthy construction of actual world knowledge into solely a single quantity. This significantly turns into a difficulty with low-data or partially-observable eventualities.
To interrupt the algorithmic bottleneck, we as a substitute decide to symbolize each the encoder and the algorithm as high-dimensional neural networks! Now, our algorithmic mannequin is a processor neural community—mapping excessive dimensional embeddings to excessive dimensional embeddings. To recuperate related outputs, we will then connect an acceptable decoder community to the output embeddings of the processor. If we had been capable of assure that this processor community “captures the computation” of the algorithm, then we’d concurrently resolve the entire points beforehand recognized:
- Our pipeline could be an end-to-end differentiable neural community;
- It will even be high-dimensional all through, assuaging the algorithmic bottleneck;
- If any computation cannot be defined by the processor, we will add skip connections going straight from the encoder to the decoder, to deal with such residual info.
So, all we’d like now’s to provide a neural community which captures computation! However, wait… that’s precisely what we have now been speaking about on this complete weblog put up! 🙂
We’ve got arrived on the neural algorithmic reasoning (NAR) blueprint [32]:
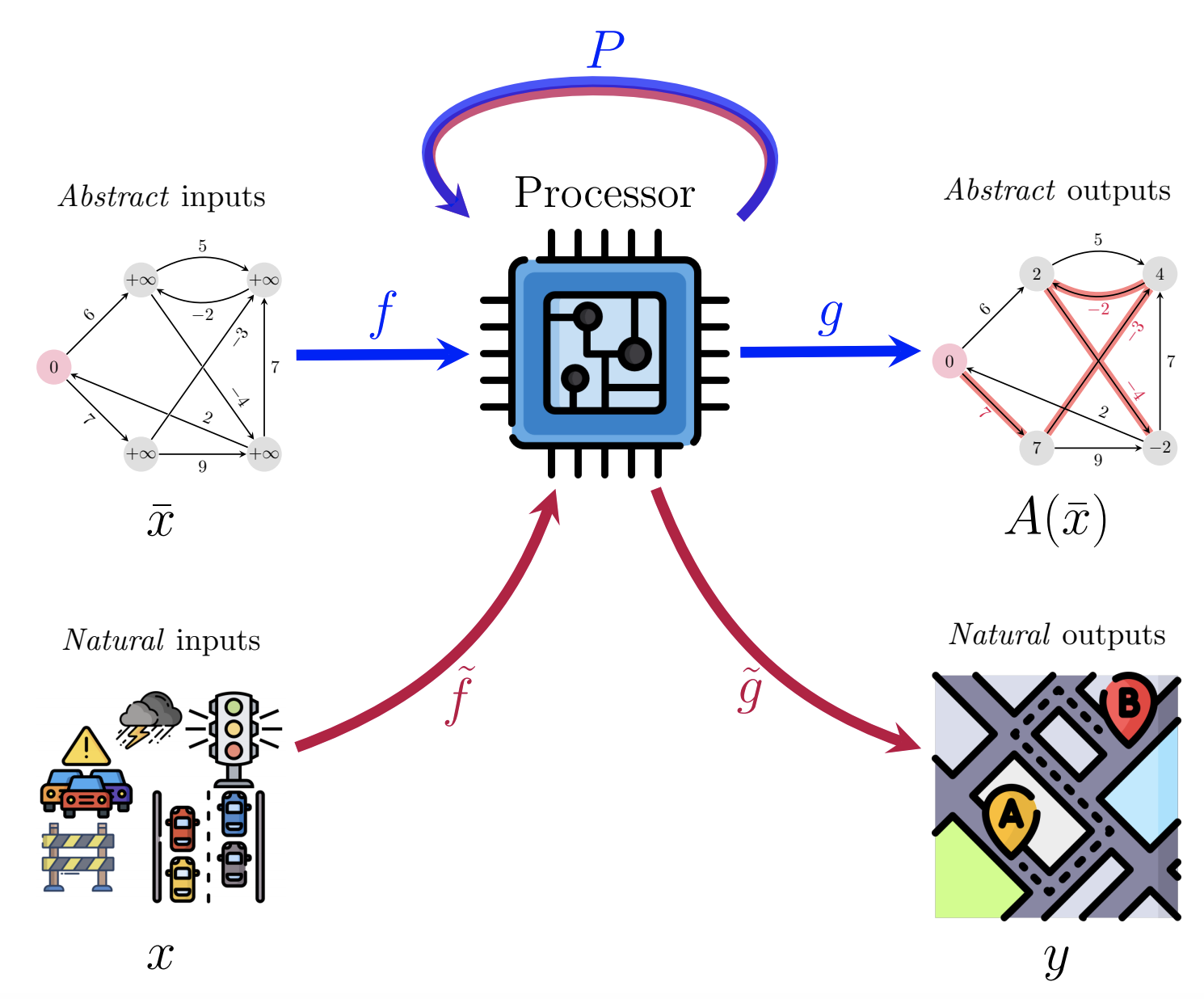
This determine represents a neat abstract of all the things we have now lined to this point: first, we get hold of an appropriate processor community, P, by algorithmic alignment to a goal algorithm, or pre-training on studying to execute the goal algorithm, or each! As soon as prepared, we embrace P into any neural pipeline we care about over uncooked (pure) knowledge. This permits us to use goal algorithms “on inputs beforehand thought-about inaccessible to them”, within the phrases of the unique NAR paper [32]. Relying on the circumstances, we might or might not want to maintain P’s parameters frozen as soon as deployed, or P might even be fully nonparametric [37,38]!
Whereas initially solely a proposal, there at the moment are a number of profitable NAR situations which were printed at top-tier venues [36,39,40,41]. Within the most-recent such paper [41], we aimed to check how one can classify blood vessels within the mouse mind—a really difficult graph activity spanning thousands and thousands of nodes and edges [42]. Nonetheless, whereas it’s not trivial to straight classify blood vessels from their options, it’s moderately secure to imagine that the principle goal of blood vessels is to conduct blood stream—therefore, an algorithm for stream evaluation could possibly be an appropriate one to deploy right here. Accordingly, we first pre-trained a NAR processor to execute the related maximum-flow and minimum-cut algorithms [43], then efficiently deployed it on the mind vessel graph, surpassing the earlier state-of-the-art GNNs. It’s worthy to notice that the mind vessel graph is 180,000x bigger than the artificial graphs we used for studying to execute, and minimal hyperparameter tuning was utilized all through! We’re assured this success is simply the primary of many.
The place can we get good processors from?
Whereas the concepts given in prior subsections hopefully present an excellent argument for the utility of capturing classical computation, in apply we nonetheless have to know which computation to seize! The entire NAR papers referenced above use goal algorithms extremely related to the downstream activity, and the processors are educated utilizing bespoke execution datasets constructed on high of these algorithms. This usually requires each area experience and laptop science experience, and therefore represents a transparent barrier of entry!
Since my beginnings in NAR, I’ve been strongly all for lowering this barrier of entry, whereas additionally offering a group of “base processors” that needs to be helpful in all kinds of duties. This resulted in a two-year-long engineering effort, culminating by open-sourcing the CLRS Algorithmic Reasoning Benchmark (https://github.com/deepmind/clrs) [44].
The CLRS benchmark was impressed by the long-lasting Introduction to Algorithms (CLRS) textbook from Cormen, Leiserson, Rivest and Stein [1], which is likely one of the hottest undergraduate textbooks on classical algorithms and knowledge buildings, and a “bible” for aggressive programmers. Regardless of its many hundreds of pages, it solely accommodates ~90 distinct algorithms, and these algorithms are inclined to type the foundations behind complete careers in software program engineering! Therefore, the algorithms in CLRS can type our desired stable set of “base processors”, and we got down to make it straightforward to assemble and practice NAR processors to execute the algorithms in CLRS.
In its first incarnation, we launched CLRS-30, a group of dataset and processor mills for thirty algorithms in CLRS, spanning all kinds of expertise: sorting, looking out, dynamic programming, graph algorithms, string algorithms and geometric algorithms.
What makes CLRS-30 particular is the wide range of knowledge, fashions and pipelines it exposes to the consumer: given an acceptable specification of the goal algorithm’s variables, an implementation of the goal algorithm, and a fascinating random enter sampler, CLRS will routinely produce the complete execution trajectories of this algorithm’s variables in a spatio-temporal graph-structured format, related encoder/decoder/processor fashions, and loss features. Because of this, we usually seek advice from CLRS as a “dataset and baseline generator” relatively than a person dataset.
For instance, here’s a CLRS-produced trajectory for insertion sorting an inventory [5, 2, 4, 3, 1]:

This trajectory absolutely exposes the inner state of the algorithm: how the listing’s pointers (in inexperienced) change over time, which factor is presently being sorted (in crimson), and the place it must be sorted into (in blue). By default, these can be utilized for step-wise supervision, though just lately extra attention-grabbing methods to make use of the trajectories, corresponding to Trace-ReLIC [21], had been proposed.
Why cease at simply one algorithm? May we be taught all thirty?
As talked about, CLRS-30 converts thirty numerous algorithms right into a unified graph illustration. This paves the best way for an apparent query: may we be taught one processor (with a single set of weights) to execute all of them? To be clear, we envision a NAR processor like this:
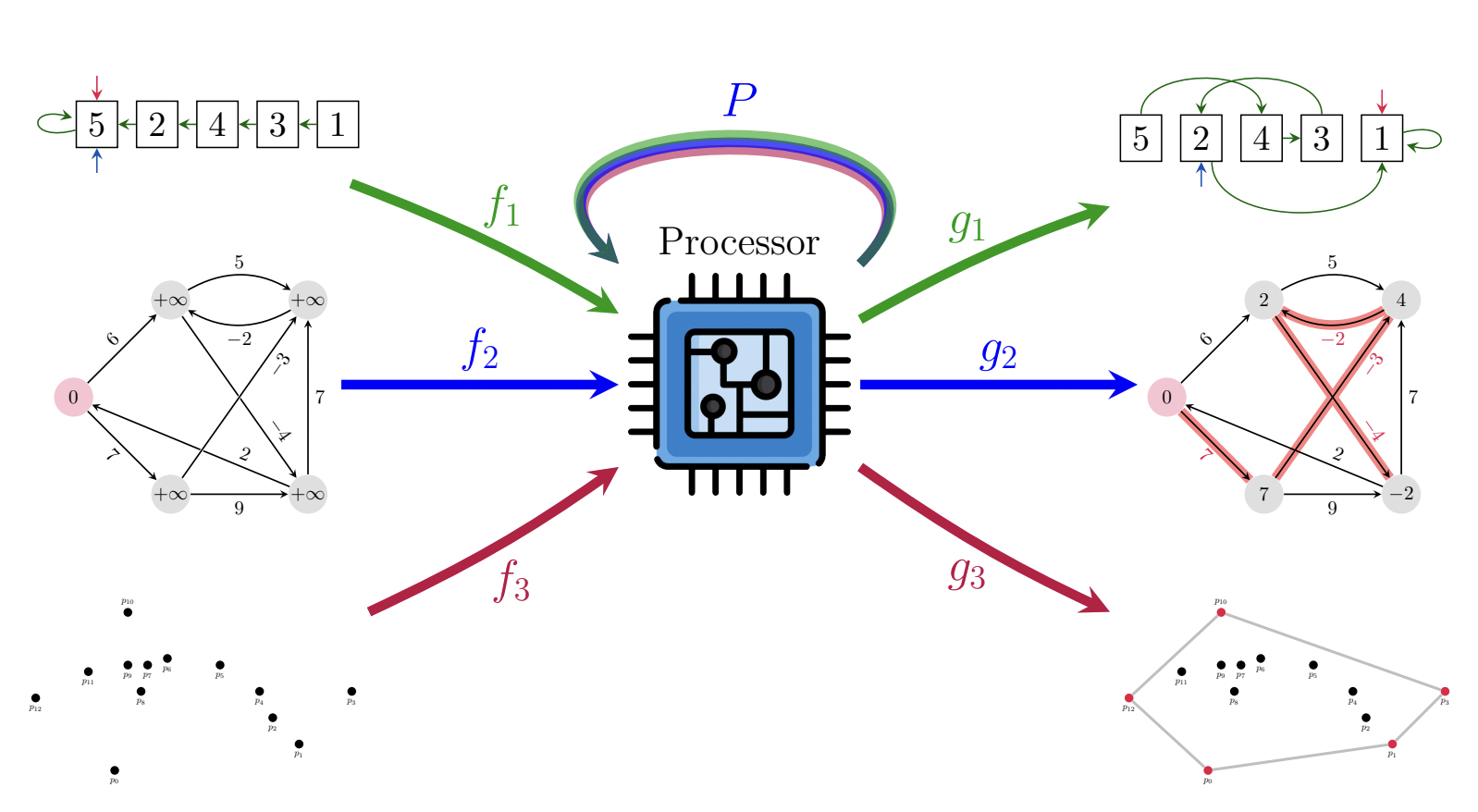
That’s, a single (G)NN, able to executing sorting, path-finding, convex hull discovering, and all different CLRS algorithms. For the reason that enter and output dimensionalities can fluctuate wildly between the totally different algorithms, we’d nonetheless suggest utilizing separate encoders and decoders for every algorithm—mapping into and out of the processor’s latent house—nonetheless, we intentionally maintain these as linear features to position nearly all of the computational effort on P.
Nonetheless, regardless of the bottom concept being easy in precept, this proves to be no trivial endeavour. Most prior makes an attempt to be taught a number of algorithms, corresponding to NEGA [7] or its successor, NE++ [45], have intentionally focussed on studying to execute extremely associated algorithms, the place the training indicators are more likely to be well-correlated. Accordingly, our preliminary single-processor multi-task coaching runs on all of CLRS-30 resulted in NaNs.
We’ve got been capable of determine single-task instabilities as the principle offender of this: if the gradients for any particular person algorithmic activity are noisy or unstable, this interprets to unstable coaching on all thirty of them. Therefore, we launched a devoted “mini-strike” of two months to determine and repair studying stability points in single-task learners. Our ensuing mannequin, Triplet-GMPNN [46], improves absolute imply efficiency over CLRS-30 by over 20% from prior state-of-the-art, and permits profitable multi-task coaching! What’s extra, we now have a single generalist Triplet-GMPNN that, on common, matches the thirty specialist Triplet-GMPNNs, evaluated out-of-distribution:
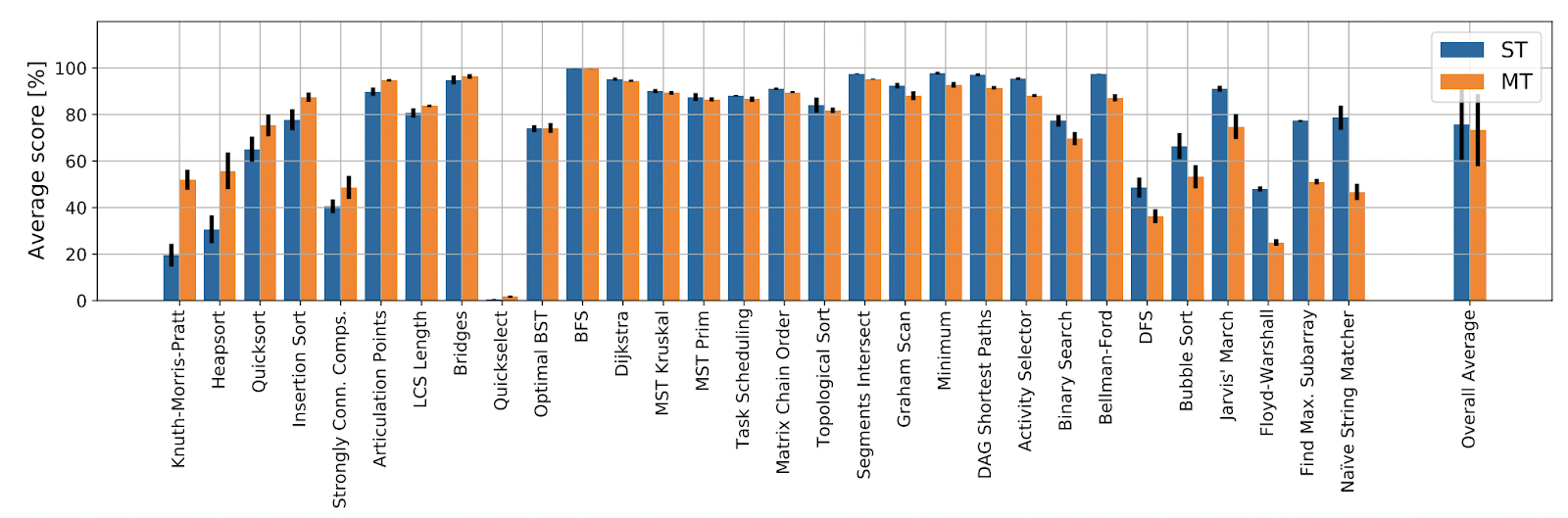
Whereas it’s evident from this plot that we nonetheless have an extended approach to go earlier than we produce a completely “algorithmic” NAR processor library, this outcome has been seen as a big “compression” milestone, just like the Gato [47] paper. The discharge of our Triplet-GMPNN mannequin sparked extraordinarily attention-grabbing discussions on Twitter, Reddit and HackerNews, particularly in gentle of its implications to setting up generally-intelligent programs. Usually, the progress in NAR made by varied teams over simply the previous three years has been unbelievable to look at. And we’re simply getting began: now that we will, in precept, construct generalist NAR processors, I’m immensely excited concerning the potential this holds for future analysis and merchandise.
Wish to know extra?
Evidently, there may be rather a lot of fabric this text doesn’t cowl—particularly, the technical and implementation particulars of lots of the papers mentioned herein. If what you’ve learn right here has made you to know extra, and even play with NAR fashions your self, I like to recommend you take a look at the LoG’22 Tutorial on NAR (https://algo-reasoning.github.io/), which I delivered alongside Andreea Deac and Andrew Dudzik. Over the course of slightly below three hours, we cowl the entire concept wanted to grasp the foundations of growing, deploying, and deepening neural algorithmic reasoners, together with plentiful code pointers and references. And naturally, you’re greater than welcome to succeed in out straight, ought to you’ve any follow-up questions, attention-grabbing factors of dialogue, and even attention-grabbing concepts for initiatives!
References
- TH. Cormen, CE. Leiserson, RL. Rivest, and C. Stein. Introduction to Algorithms. MIT Press’22.
- Ok. Xu, J. Li, M. Zhang, SS. Du, Ok-I. Kawarabayashi, and S. Jegelka. What Can Neural Networks Purpose About?. ICLR’20.
- P. Veličković. Every thing is Related: Graph Neural Networks. Present Opinion in Structural Biology’23.
- R. Bellman. On a Routing Downside. Quarterly of Utilized Arithmetic’58.
- R. Bellman. Dynamic Programming. Science’66.
- P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Liò, and Y. Bengio. Graph Consideration Networks. ICLR’18.
- P. Veličković, R. Ying, M. Padovano, R. Hadsell, and C. Blundell. Neural Execution of Graph Algorithms. ICLR’20.
- JB. Hamrick, KR. Allen, V. Bapst, T. Zhu, KR. McKee, JB. Tenenbaum, and PW. Battaglia. Relational inductive biases for bodily building in people and machines. CCS’18.
- Ok. Xu*, W. Hu*, J. Leskovec, and S. Jegelka. How Highly effective are Graph Neural Networks?. ICLR’19.
- Ok. Xu, M. Zhang, J. Li, SS. Du, Ok-I. Kawarabayashi, and S. Jegelka. How Neural Networks Extrapolate: From Feedforward to Graph Neural Networks. ICLR’21.
- J. Uesato*, N. Kushman*, R. Kumar*, F. Music, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins. Fixing math phrase issues with process- and outcome-based suggestions. arXiv’22.
- H. Lightman*, V. Kosaraju*, Y. Burda*, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and Ok. Cobbe. Let’s Confirm Step by Step. arXiv’23.
- A. Graves, G. Wayne, and I. Danihelka. Neural Turing Machines. arXiv’14.
- A. Graves, G. Wayne, M. Reynolds, T. Harley, I. Danihelka, A. Grabska-Barwińska, S. Gómez Colmenarejo, E. Grefenstette, T. Ramalho, J. Agapiou, A. Puigdomènech Badia, KM. Hermann, Y. Zwols, G. Ostrovski, A. Cain, H. King, C. Summerfield, P. Blunsom, Ok. Kavukcuoglu, and D. Hassabis. Hybrid computing utilizing a neural community with dynamic exterior reminiscence. Nature’16.
- A. Vaswani*, N. Shazeer*, N. Parmar*, J. Uszkoreit*, L. Jones*, AN. Gomez*, Ł. Kaiser*, and I. Polosukhin*. Consideration is all you want. NeurIPS’17.
- Ok. Freivalds, E. Ozoliņš, and A. Šostaks. Neural Shuffle-Change Networks – Sequence Processing in O(n log n) Time. NeurIPS’19.
- H. Tang, Z. Huang, J. Gu, B-L. Lu, and H. Su. In the direction of Scale-Invariant Graph-related Downside Fixing by Iterative Homogeneous GNNs. NeurIPS’20.
- P. Veličković, L. Buesing, MC. Overlan, R. Pascanu, O. Vinyals, and C. Blundell. Pointer Graph Networks. NeurIPS’20.
- H. Strathmann, M. Barekatain, C. Blundell, and P. Veličković. Persistent Message Passing. ICLR’21 SimDL.
- B. Bevilacqua, Y. Zhou, and B. Ribeiro. Dimension-invariant graph representations for graph classification extrapolations. ICML’21.
- B. Bevilacqua, Ok. Nikiforou*, B. Ibarz*, I. Bica, M. Paganini, C. Blundell, J. Mitrovic, and P. Veličković. Neural Algorithmic Reasoning with Causal Regularisation. ICML’23.
- A. Dudzik*, and P. Veličković*. Graph Neural Networks are Dynamic Programmers. NeurIPS’22.
- A. Dudzik, T. von Glehn, R. Pascanu, and P. Veličković. Asynchronous Algorithmic Alignment with Cocycles. ICML’23 KLR.
- A. Davies, P. Veličković, L. Buesing, S. Blackwell, D. Zheng, N. Tomašev, R. Tanburn, P. Battaglia, C. Blundell, A. Juhász, M. Lackenby, G. Williamson, D. Hassabis, and P. Kohli. Advancing arithmetic by guiding human instinct with AI. Nature’21.
- A. Davies, A. Juhász, M. Lackenby, and N. Tomašev. The signature and cusp geometry of hyperbolic knots. Geometry & Topology (in press).
- C. Blundell, L. Buesing, A. Davies, P. Veličković, and G. Williamson. In the direction of combinatorial invariance for Kazhdan-Lusztig polynomials. Illustration Principle’22.
- L. Beurer-Kellner, M. Vechev, L. Vanbever, and P. Veličković. Studying to Configure Laptop Networks with Neural Algorithmic Reasoning. NeurIPS’22.
- EW. Dijkstra. A be aware on two papers in reference to graphs. Numerische Matematik’59.
- A. Derrow-Pinion, J. She, D. Wong, O. Lange, T. Hester, L. Perez, M. Nunkesser, S. Lee, X. Guo, B. Wiltshire, PW. Battaglia, V. Gupta, A. Li, Z. Xu, A. Sanchez-Gonzalez, Y. Li, and P. Veličković. ETA Prediction with Graph Neural Networks in Google Maps. CIKM’21.
- TE. Harris, and FS. Ross. Fundamentals of a way for evaluating rail web capacities. RAND Tech Report’55.
- M. Winkenbach, S. Parks, and J. Noszek. Technical Proceedings of the Amazon Final Mile Routing Analysis Problem. 2021.
- P. Veličković, and C. Blundell. Neural Algorithmic Reasoning. Patterns’21.
- A. Krizhevsky, I. Sutskever, and GE. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. NeurIPS’12.
- Q. Cappart, D. Chételat, EB. Khalil, A. Lodi, C. Morris, and P. Veličković. Combinatorial optimization and reasoning with graph neural networks. JMLR’23.
- M. Vlastelica*, A. Paulus*, V. Musil, G. Martius, and M. Rolínek. Differentiation of Blackbox Combinatorial Solvers. ICLR’20.
- A. Deac, P. Veličković, O. Milinković, P-L. Bacon, J. Tang, and M. Nikolić. Neural Algorithmic Reasoners are Implicit Planners. NeurIPS’21.
- B. Wilder, E. Ewing, B. Dilkina, and M. Tambe. Finish to finish studying and optimization on graphs. NeurIPS’19.
- M. Garnelo, and WM. Czarnecki. Exploring the House of Key-Worth-Question Fashions with Intention. 2023.
- Y. He, P. Veličković, P. Liò, and A. Deac. Steady Neural Algorithmic Planners. LoG’22.
- P. Veličković*, M. Bošnjak*, T. Kipf, A. Lerchner, R. Hadsell, R. Pascanu, and C. Blundell. Reasoning-Modulated Representations. LoG’22.
- D. Numeroso, D. Bacciu, and P. Veličković. Twin Algorithmic Reasoning. ICLR’23.
- JC. Paetzold, J. McGinnis, S. Shit, I. Ezhov, P. Büschl, C. Prabhakar, MI. Todorov, A. Sekuboyina, G. Kaissis, A. Ertürk, S. Günnemann, and BH. Menze. Entire Mind Vessel Graphs: A Dataset and Benchmark for Graph Studying and Neuroscience. NeurIPS’21 Datasets and Benchmarks.
- LR. Ford, and DR. Fulkerson. Maximal stream by means of a community. Canadian Journal of Arithmetic’56.
- P. Veličković, A. Puigdomènech Badia, D. Budden, R. Pascanu, A. Banino, M. Dashevskiy, R. Hadsell, and C. Blundell. The CLRS Algorithmic Reasoning Benchmark. ICML’22.
- L-PAC. Xhonneux, A. Deac, P. Veličković, and J. Tang. Methods to switch algorithmic reasoning data to be taught new algorithms?. NeurIPS’21.
- B. Ibarz, V. Kurin, G. Papamakarios, Ok. Nikiforou, M. Bennani, R. Csordás, A. Dudzik, M. Bošnjak, A. Vitvitskyi, Y. Rubanova, A. Deac, B. Bevilacqua, Y. Ganin, C. Blundell, and P. Veličković. A Generalist Neural Algorithmic Learner. LoG’22.
- S. Reed*, Ok. Żołna*, E. Parisotto*, S. Gómez Colmenarejo, A. Novikov, G. Barth-Maron, M. Giménez, Y. Sulsky, J. Kay, JT. Springenberg, T. Eccles, J. Bruce, A. Razavi, A. Edwards, N. Heess, Y. Chen, R. Hadsell, O. Vinyals, M. Bordbar, and N. de Freitas. A Generalist Agent. TMLR’22.
Writer Bio
Petar Veličković is a Employees Analysis Scientist at Google DeepMind, Affiliated Lecturer on the College of Cambridge, and an Affiliate of Clare Corridor, Cambridge. Petar holds a PhD in Laptop Science from the College of Cambridge (Trinity School), obtained below the supervision of Pietro Liò. His analysis issues geometric deep studying—devising neural community architectures that respect the invariances and symmetries in knowledge (a subject he is co-written a proto-book about).
Quotation
For attribution in tutorial contexts or books, please cite this work as
Petar Veličković, "Neural Algorithmic Reasoning", The Gradient, 2023.
BibTeX quotation:
@article{veličković2023nar,
creator = {Veličković, Petar},
title = {Neural Algorithmic Reasoning},
journal = {The Gradient},
12 months = {2023},
howpublished = {url{https://thegradient.pub/neural-algorithmic-reasoning/},
}
{kind=link}