[ad_1]
What’s the Position of Arithmetic in Trendy Machine Studying?
The previous decade has witnessed a shift in how progress is made in machine studying. Analysis involving rigorously designed and mathematically principled architectures end in solely marginal enhancements whereas compute-intensive and engineering-first efforts that scale to ever bigger coaching units and mannequin parameter counts end in exceptional new capabilities unpredicted by present idea. Arithmetic and statistics, as soon as the first guides of machine studying analysis, now wrestle to supply speedy perception into the newest breakthroughs. This isn’t the primary time that empirical progress in machine studying has outpaced extra theory-motivated approaches, but the magnitude of latest advances has pressured us to swallow the bitter capsule of the “Bitter Lesson” but once more [1].
This shift has prompted hypothesis about arithmetic’ diminished position in machine studying analysis transferring ahead. It’s already evident that arithmetic must share the stage with a broader vary of views (for example, biology which has deep expertise drawing conclusions about irreducibly advanced techniques or the social sciences as AI is built-in ever extra deeply into society). The more and more interdisciplinary nature of machine studying ought to be welcomed as a optimistic improvement by all researchers.
Nonetheless, we argue that arithmetic stays as related as ever; its position is just evolving. For instance, whereas arithmetic may as soon as have primarily offered theoretical ensures on mannequin efficiency, it could quickly be extra generally used for post-hoc explanations of empirical phenomena noticed in mannequin coaching and efficiency–a job analogous to at least one that it performs in physics. Equally, whereas mathematical instinct may as soon as have guided the design of handcrafted options or architectural particulars at a granular degree, its use might shift to higher-level design decisions equivalent to matching structure to underlying process construction or knowledge symmetries.
None of that is fully new. Arithmetic has at all times served a number of functions in machine studying. In any case, the interpretation equivariant convolutional neural community, which exemplifies the concept of structure matching knowledge symmetries talked about above is now over 40 years previous. What’s altering are the sorts of issues the place arithmetic could have the best influence and the methods it should mostly be utilized.
An intriguing consequence of the shift in direction of scale is that it has broadened the scope of the fields of arithmetic relevant to machine studying. “Pure” mathematical domains equivalent to topology, algebra, and geometry, at the moment are becoming a member of the extra historically utilized fields of likelihood idea, evaluation, and linear algebra. These pure fields have grown and developed over the past century to deal with excessive ranges of abstraction and complexity, serving to mathematicians make discoveries about areas, algebraic objects, and combinatorial processes that in the first place look appear past human instinct. These capabilities promise to handle lots of the greatest challenges in trendy deep studying.
On this article we’ll discover a number of areas of present analysis that show the enduring potential of arithmetic to information the method of discovery and understanding in machine studying.

Determine 1: Arithmetic can illuminate the ways in which ReLU-based neural networks shatter enter area into numerous polygonal areas, in every of which the mannequin behaves like a linear map [2, 3, 4]. These decompositions create stunning patterns. (Determine made with SplineCam [5]).
Describing an Elephant from a Pin Prick
Suppose you’re given a 7 billion parameter neural community with 50 layers and are requested to research it; how would you start? The usual process could be to calculate related efficiency statistics. As an example, the accuracy on a set of analysis benchmarks. In sure conditions, this can be enough. Nonetheless, deep studying fashions are advanced and multifaceted. Two laptop imaginative and prescient fashions with the identical accuracy might have very totally different generalization properties to out-of-distribution knowledge, calibration, adversarial robustness, and different “secondary statistics” which are vital in lots of real-world purposes. Past this, all proof means that to construct a whole scientific understanding of deep studying, we might want to enterprise past analysis scores. Certainly, simply as it’s unimaginable to seize all the size of humanity with a single numerical amount (e.g., IQ, peak), making an attempt to grasp a mannequin by one and even a number of statistics alone is basically limiting.
One distinction between understanding a human and understanding a mannequin is that we now have easy accessibility to all mannequin parameters and all the person computations that happen in a mannequin. Certainly, by extracting a mannequin’s hidden activations we will immediately hint the method by which a mannequin converts uncooked enter right into a prediction. Sadly, the world of hidden activations is much much less hospitable than that of easy mannequin efficiency statistics. Just like the preliminary enter, hidden activations are often excessive dimensional, however not like enter knowledge they don’t seem to be structured in a kind that people can perceive. If we enterprise into even greater dimensions, we will attempt to perceive a mannequin by way of its weights immediately. Right here, within the area of mannequin weights, we now have the liberty to maneuver in thousands and thousands to billions of orthogonal instructions from a single start line. How can we even start to make sense of those worlds?
There’s a well-known fable during which three blind males every really feel a special a part of an elephant. The outline that every offers of the animal is totally totally different, reflecting solely the physique half that that man felt. We argue that not like the blind males who can no less than use their hand to really feel a considerable a part of one of many elephant’s physique elements, present strategies of analyzing the hidden activations and weights of a mannequin are akin to making an attempt to explain the elephant from the contact of a single pin.
Instruments to Characterize What We Can’t Visualize
Regardless of the favored notion that mathematicians solely deal with fixing issues, a lot of analysis arithmetic entails understanding the suitable inquiries to ask within the first place. That is pure since lots of the objects that mathematicians examine are up to now faraway from on a regular basis expertise that we begin with very restricted instinct for what we will hope to truly perceive. Substantial effort is commonly required to construct up instruments that can allow us to leverage our present instinct and obtain tractable outcomes that improve our understanding. The idea of a rotation supplies a pleasant instance of this case since these are very acquainted in 2- and 3-dimensions, however turn into much less and fewer accessible to on a regular basis instinct as their dimension grows bigger. On this latter case, the differing views offered by pure arithmetic turn into increasingly essential to gaining a extra holistic perspective on what these truly are.
Those that know slightly linear algebra will do not forget that rotations generalize to greater dimensions and that in $n$-dimensions they are often realized by $n occasions n$ orthogonal matrices with determinant $1$. The set of those are generally written as $SO(n)$ and referred to as the particular orthogonal group. Suppose we need to perceive the set of all $n$-dimensional rotations. There are lots of complementary approaches to doing this. We will discover the linear algebraic construction of all matrices in $SO(n)$ or examine $SO(n)$ based mostly on how every aspect behaves as an operator appearing on $mathbb{R}^n$.
Alternatively, we will additionally attempt to use our innate spatial instinct to grasp $SO(n)$. This seems to be a strong perspective in math. In any dimension $n$, $SO(n)$ is a geometrical object referred to as a manifold. Very roughly, an area that domestically seems to be like Euclidean area, however which can have twists, holes, and different non-Euclidean options once we zoom out. Certainly, whether or not we make it exact or not, all of us have a way of whether or not two rotations are “shut” to one another. For instance, the reader would in all probability agree that $2$-dimensional rotations of $90^circ$ and $91^circ$ “really feel” nearer than rotations of $90^circ$ and $180^circ$. When $n=2$, one can present that the set of all rotations is geometrically “equal” to a $1$-dimensional circle. So, a lot of what we all know in regards to the circle will be translated to $SO(2)$.
What occurs once we need to examine the geometry of rotations in $n$-dimensions for $n > 3$? If $n = 512$ (a latent area for example), this quantities to finding out a manifold in $512^2$-dimensional area. Our visible instinct is seemingly ineffective right here since it isn’t clear how ideas which are acquainted in 2- and 3-dimensions will be utilized in $512^2$-dimensions. Mathematicians have been confronting the issue of understanding the un-visualizable for a whole bunch of years. One technique is to search out generalizations of acquainted spatial ideas from $2$ and $3$-dimensions to $n$-dimensions that join with our instinct.
This method is already getting used to raised perceive and characterize experimental observations in regards to the area of mannequin weights, hidden activations, and enter knowledge of deep studying fashions. We offer a style of such instruments and purposes right here:
- Intrinsic Dimension: Dimension is an idea that’s acquainted not solely from our expertise within the spatial dimensions that we will readily entry, 1-, 2-, and 3-dimensions, but additionally from extra casual notions of “levels of freedom” in on a regular basis techniques equivalent to driving a automobile (ahead/again, turning the steering wheel both left or proper). The notion of dimension arises naturally within the context of machine studying the place we might need to seize the variety of impartial methods during which a dataset, discovered illustration, or assortment of weight matrices truly differ.
In formal arithmetic, the definitions of dimension rely upon the form of area one is finding out however all of them seize some side of this on a regular basis instinct. As a easy instance, if I stroll alongside the perimeter of a circle, I’m solely capable of transfer ahead and backward, and thus the dimension of this area is $1$. For areas just like the circle that are manifolds, dimension will be formally outlined by the truth that a small enough neighborhood round every level seems to be like a subset of some Euclidean area $mathbb{R}^okay$. We then say that the manifold is $okay$-dimensional. If we zoom in on a small phase of the circle, it nearly seems to be like a phase of $mathbb{R} = mathbb{R}^1$, and therefore the circle is $1$-dimensional.
The manifold speculation posits that many forms of knowledge (no less than roughly) reside on a low-dimensional manifold although they’re embedded in a high-dimensional area. If we assume that that is true, it is smart that the dimension of this underlying manifold, referred to as the intrinsic dimension of the information, is one method to describe the complexity of the dataset. Researchers have estimated intrinsic dimension for widespread benchmark datasets, displaying that intrinsic dimension seems to be correlated to the convenience with which fashions generalize from coaching to check units [6], and might clarify variations in mannequin efficiency and robustness in several domains equivalent to medical pictures [7]. Intrinsic dimension can also be a elementary ingredient in some proposed explanations of information scaling legal guidelines [8, 9], which underlie the race to construct ever greater generative fashions.
Researchers have additionally famous that the intrinsic dimension of hidden activations have a tendency to alter in a attribute method as info passes by way of the mannequin [10, 11] or over the course of the diffusion course of [12]. These and different insights have led to using intrinsic dimension in detection of adversarial examples [13], AI-generated content material [14], layers the place hidden activations include the richest semantic content material [11], and hallucinations in generative fashions [15].
- Curvature: Whereas segments of the circle might look “straight” once we zoom up shut sufficient, their curvature implies that they are going to by no means be precisely linear as a straight line is. The notion of curvature is a well-known one and as soon as formalized, it affords a method of rigorously measuring the extent to which the realm round a degree deviates from being linear. Care should be taken, nonetheless. A lot of our on a regular basis instinct about curvature assumes a single dimension. On manifolds with dimension $2$ or larger, there are a number of, linearly impartial instructions that we will journey away from a degree and every of those might have a special curvature (within the $1$-dimensional sense). In consequence, there are a number of various generalizations of curvature for higher-dimensional areas, every with barely totally different properties.
The notion of curvature has performed a central position in deep studying, particularly with respect to the loss panorama the place modifications in curvature have been used to research coaching trajectories [16]. Curvature can also be central to an intriguing phenomenon often called the ‘fringe of stability’, whereby the curvature of the loss panorama over the course of coaching will increase as a operate of studying price till it hovers across the level the place the coaching run is near changing into unstable [17]. In one other route, curvature has been used to calculate the extent that mannequin predictions change as enter modifications. As an example, [18] offered proof that greater curvature in determination boundaries correlates with greater vulnerability to adversarial examples and instructed a brand new regularization time period to cut back this. Lastly, motivated by work in neuroscience, [19] offered a technique that makes use of curvature to spotlight attention-grabbing variations in illustration between the uncooked coaching knowledge and a neural community’s inside illustration. A community might stretch and broaden elements of the enter area, producing areas of excessive curvature because it magnifies the illustration of coaching examples which have a better influence on the loss operate.
- Topology: Each dimension and curvature seize native properties of an area that may be measured by trying on the neighborhood round a single level. Then again, probably the most notable characteristic of our working instance, the circle, is neither its dimension nor its curvature, however fairly the truth that it’s round. We will solely see this side by analyzing the entire area without delay. Topology is the sphere of arithmetic that focuses on such “world” properties.
Topological instruments equivalent to homology, which counts the variety of holes in an area, has been used to light up the way in which that neural networks course of knowledge, with [20] displaying that deep studying fashions “untangle” knowledge distributions, decreasing their complexity layer by layer. Variations of homology have additionally been utilized to the weights of networks to raised perceive their structural options, with [21] displaying that such topological statistics can reliably predict optimum early-stopping occasions. Lastly, since topology supplies frameworks that seize the worldwide facets of an area, it has proved a wealthy supply of concepts for how you can design networks that seize greater order relationships inside knowledge, resulting in a spread of generalizations of graph neural networks constructed on high of topological constructions [22, 23, 24, 25].
Whereas the examples above have every been helpful for gaining perception into phenomena associated to deep studying, they had been all developed to handle challenges in different fields. We consider {that a} greater payoff will come when the neighborhood makes use of the geometric paradigm described right here to construct new instruments particularly designed to handle the challenges that deep studying poses. Progress on this route has already begun. Assume for example of linear mode connectivity which has helped us to raised perceive the loss panorama of neural networks [26] or work across the linear illustration speculation which has helped to light up the way in which that ideas are encoded within the latent area of enormous language fashions [27]. One of the crucial thrilling occurrences in arithmetic is when the instruments from one area present sudden perception in one other. Consider the invention that Riemannian geometry supplies a few of the mathematical language wanted for normal relativity. We hope {that a} comparable story will finally be instructed for geometry and topology’s position in deep studying.
Symmetries in knowledge, symmetries in fashions
Symmetry is a central theme in arithmetic, permitting us to interrupt an issue into easier elements which are simpler to resolve. Symmetry has lengthy performed an essential position in machine studying, notably laptop imaginative and prescient. Within the basic canine vs. cat classification process for example, a picture that incorporates a canine continues to include a canine no matter whether or not we transfer the canine from one a part of the picture to a different, whether or not we rotate the canine, or whether or not we replicate it. We are saying that the duty is invariant to picture translation, rotation, and reflection.
The notion of symmetry is mathematically encoded within the idea of a group, which is a set $G$ geared up with a binary operation $star$ that takes two components of $G$, $g_1$, $g_2$ as enter and produces a 3rd $g_1star g_2$ as output. You’ll be able to consider the integers $mathbb{Z}$ with the binary operation of addition ($star = +$) or the non-zero actual numbers with the binary operation of multiplication ($star = occasions$). The set of $n$-dimensional rotations, $SO(n)$, additionally varieties a bunch. The binary operation takes two rotations and returns a 3rd rotation that’s outlined by merely making use of the primary rotation after which making use of the second.
Teams fulfill axioms that make sure that they seize acquainted properties of symmetries. For instance, for any symmetry transformation, there ought to be an inverse operation that undoes the symmetry. If I rotate a circle by $90^{circ}$, then I can rotate it again by $-90^{circ}$ and return to the place I began. Discover that not all transformations fulfill this property. As an example, there isn’t a well-defined inverse for downsampling a picture. Many various pictures downsample to the identical (smaller) picture.
Within the earlier part we gave two definitions of $SO(n)$: the primary was the geometric definition, as rotations of $mathbb{R}^n$, and the second was as a particular subset of $n occasions n$ matrices. Whereas the previous definition could also be handy for our instinct, the latter has the profit that linear algebra is one thing that we perceive fairly effectively at a computational degree. The conclusion of an summary group as a set of matrices is named a linear illustration and it has confirmed to be one of the vital fruitful strategies of finding out symmetry. It is usually the way in which that symmetries are often leveraged when performing computations (for instance, in machine studying).
We noticed just a few examples of symmetries that may be discovered within the knowledge of a machine studying process, equivalent to the interpretation, rotation, and reflection symmetries in laptop imaginative and prescient issues. Contemplate the case of a segmentation mannequin. If one rotates an enter picture by $45^{circ}$ after which places it by way of the mannequin, we’ll hope that we get a $45^{circ}$ rotation of the segmentation prediction for the un-rotated picture (that is illustrated in 1). In any case, we haven’t modified the content material of the picture.
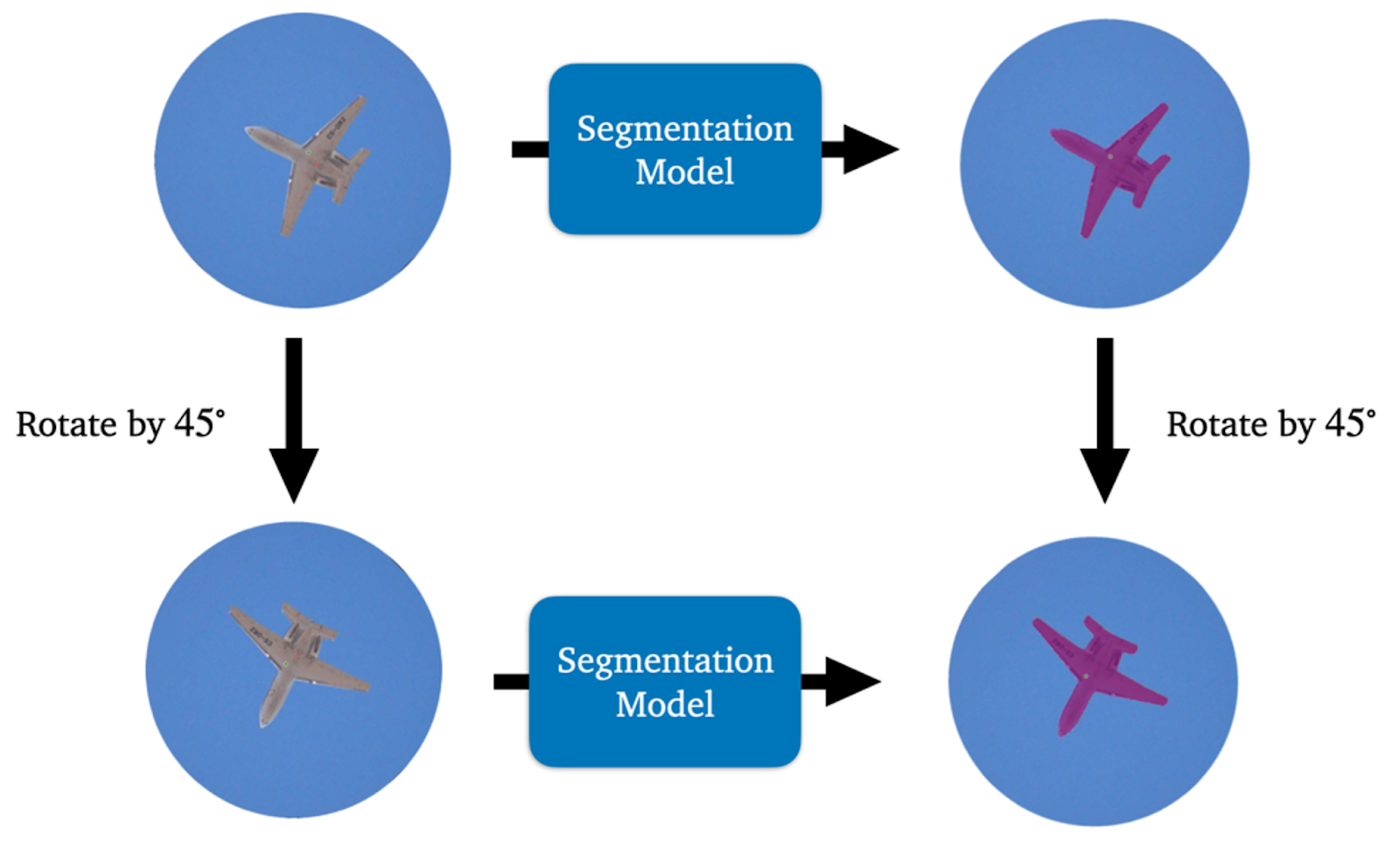
Determine 2: The idea of rotation equivariance illustrated for a segmentation mannequin. One will get the identical output no matter whether or not one rotates first after which applies the community or applies the community after which rotates.
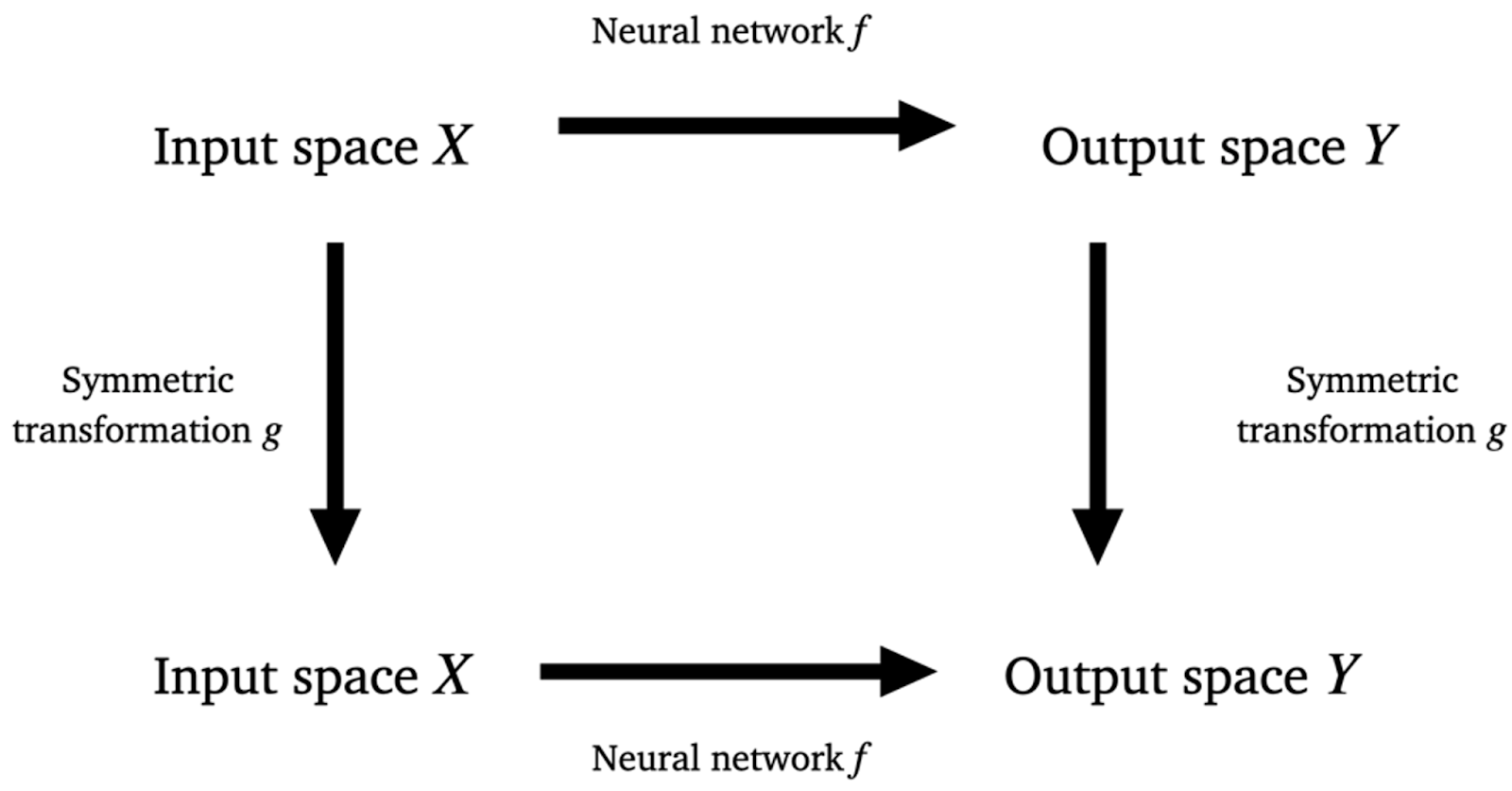
Determine 3: Equivariance holds when taking the highest path (making use of the community first after which the symmetry motion) offers the identical consequence as taking the underside path (making use of the symmetry transformation after which the community).
This property of a operate (together with neural networks), that making use of a symmetry transformation earlier than the operate yields the identical consequence as making use of the symmetry transformation after the operate is named equivariance and will be captured by the diagram in Determine 3. The important thing level is that we get the identical consequence whether or not we observe the higher path (making use of the community first after which making use of the group motion) as once we observe the decrease path (making use of the group first after which making use of the community). Conveniently, the idea of invariance, the place making use of a symmetry operation to enter has no impact on the output of the operate is a particular case of equivariance the place the motion on the output area is outlined to be trivial (making use of symmetry actions does nothing).
Invariance and equivariance in deep studying fashions will be helpful for just a few causes. Firstly, such a mannequin will yield extra predictable and constant outcomes throughout symmetry transformations. Secondly, by way of equivariance we will typically simplify the educational course of with fewer parameters (evaluate the variety of parameters in a convolutional neural community and an MLP of comparable efficiency) and fewer modes of variation to study within the knowledge (a rotation invariant picture classifier solely must study one orientation of every object fairly than all attainable orientations).
However how can we make sure that our mannequin is equivariant? A technique is to construct our community with layers which are equivariant by design. By far probably the most well-known instance of that is the convolutional neural community, whose layers are (roughly) equivariant to picture translation. That is one cause why utilizing a convolutional neural community for canine vs cat classification doesn’t require studying to acknowledge a canine at each location in a picture as it’d with an MLP. With slightly thought, one can typically give you layers that are equivariant to a particular group. Sadly, being constrained to equivariant layers that we discover in an ad-hoc method typically leaves us with a community with built-in equivariance however restricted expressivity.
Fortuitously, for many symmetry teams arising in machine studying, illustration idea affords a complete description of all attainable linear equivariant maps. Certainly, it’s a stunning mathematical truth that each one such maps are constructed from atomic constructing blocks referred to as irreducible representations. Fortunately, in lots of circumstances, the variety of these irreducible representations is finite. Understanding the irreducible representations of a bunch will be fairly highly effective. These accustomed to the ever present discrete Fourier remodel (DFT) of a sequence of size $n$ are already accustomed to the irreducible representations of 1 group, the cyclic group generated by a rotation by $360 ^{circ}/n$ (although we word that transferring between the outline we give right here and the outline of the DFT discovered within the sign processing literature takes slightly thought).
There’s now a wealthy discipline of analysis in deep studying that makes use of group representations to systematically construct expressive equivariant architectures. Some examples of symmetries which have been notably well-studied embrace: rotation and reflection of pictures [28, 29, 30, 31], three-d rotation and translation of molecular buildings [32] or level clouds [33], and permutations for studying on units [34] or nodes of a graph [35]. Encoding equivariance to extra unique symmetries has additionally confirmed helpful for areas equivalent to theoretical physics [36] and data-driven optimization [37].
Equivariant layers and different architectural approaches to symmetry consciousness are a main instance of utilizing arithmetic to inject high-level priors right into a mannequin. Do these approaches symbolize the way forward for studying within the face of information symmetries? Anecdotally, the most typical method to studying on knowledge with symmetries continues to be utilizing sufficient coaching knowledge and sufficient knowledge augmentation for the mannequin to study to deal with the symmetries by itself. Two years in the past, the writer would have speculated that these latter approaches solely work for easy circumstances, equivalent to symmetries in 2-dimensions, and might be outperformed by fashions that are equivariant by design when symmetries turn into extra advanced. But, we proceed to be shocked by the facility of scale. In any case, AlphaFold3 [38] makes use of a non-equivariant structure regardless of studying on knowledge with a number of primary symmetries. We speculate that there could also be a threshold on the ratio of symmetry complexity on the one hand and the quantity of coaching knowledge on the opposite, that determines whether or not built-in equivariance will outperform discovered equivariance [39, 40].
If that is true, we will count on to see fashions transfer away from bespoke equivariant architectures as bigger datasets turn into accessible for a particular utility. On the identical time, since compute will at all times be finite, we predict that there might be some purposes with exceptionally advanced symmetries that can at all times require some built-in priors (for instance, AI for math or algorithmic issues). No matter the place we land on this spectrum, mathematicians can stay up for an attention-grabbing comparability of the methods people inject symmetry into fashions vs the way in which that fashions study symmetries on their very own [41, 42].

Determine 4: A cartoon illustrating why including a permutation and its inverse earlier than and after a pointwise nonlinearity produces an equal mannequin (although the weights might be totally different). Since permutations will be realized by permutation matrices, the crossed arrows on the suitable will be merged into the fully-connected layer.
In fact, symmetry isn’t solely current in knowledge but additionally within the fashions themselves. As an example, the activations of hidden layers of a community are invariant to permutation. We will permute activations earlier than getting into the non-linearity and if we un-permute them afterward, the mannequin (as a operate) doesn’t change (Determine 4). Because of this we now have a straightforward recipe for producing an exponentially massive variety of networks which have totally different weights however behave identically on knowledge.
Whereas easy, this remark produces some sudden outcomes. There’s proof, for example, that whereas the loss panorama of neural networks is very non-convex, it could be a lot much less non-convex once we contemplate all networks that may be produced by way of this permutation operation as equal [43, 44]. Because of this your community and my community is probably not related by a linear path of low loss, however such a path might exist between your community and a permutation of my community. Different analysis has checked out whether or not it could be attainable to make use of symmetries to speed up optimization by ‘teleporting’ a mannequin to a extra favorable location within the loss panorama [45, 46]. Lastly, permutation symmetries additionally present one sort of justification for an empirical phenomenon the place particular person neurons in a community are inclined to encode extra semantically significant info than arbitrary linear combos of such neurons [47].
Taming Complexity with Abstraction
When discussing symmetry, we used the diagram in Determine 3 to outline equivariance. One of many virtues of this method is that we by no means needed to specify particulars in regards to the enter knowledge or structure that we used. The areas may very well be vector areas and the maps linear transformations, they may very well be neural networks of a particular structure, or they may simply be units and arbitrary capabilities between them–the definition is legitimate for every. This diagrammatic perspective, which seems to be at mathematical constructions when it comes to the composition of maps between objects fairly than the objects themselves, has been very fruitful in arithmetic and is one gateway to the topic often called class idea. Class idea is now the lingua franca in lots of areas of arithmetic because it permits mathematicians to translate definitions and outcomes throughout a variety of contexts.
In fact, deep studying is at its core all about operate composition, so it’s no nice leap to try to join it to the diagrammatic custom in arithmetic. The main focus of operate composition within the two disciplines is totally different, nonetheless. In deep studying we take easy layers that alone lack expressivity and compose them collectively to construct a mannequin able to capturing the complexity of real-world knowledge. With this comes the tongue-in-cheek demand to “stack extra layers!”. Class idea as a substitute tries to discover a common framework that captures the essence of buildings showing all through arithmetic. This enables mathematicians to uncover connections between issues that look very totally different at first look. As an example, class idea offers us the language to explain how the topological construction of a manifold will be encoded in teams by way of homology or homotopy idea.
It may be an attention-grabbing train to attempt to discover a diagrammatic description of acquainted constructions just like the product of two units $X$ and $Y$. Focusing our consideration on maps fairly than objects we discover that what characterizes $X occasions Y$ is the existence of the 2 canonical projections $pi_1$ and $pi_2$, the previous sending $(x,y) mapsto x$ and $(x,y) mapsto y$ (no less than in additional acquainted settings the place $X$ and $Y$ are, for instance, units). Certainly, the product $X occasions Y$ (no matter whether or not $X$ and $Y$ are units, vectors areas, and so forth.) is the distinctive object such that for any $Z$ with maps $f_1: Z rightarrow X$ and $f_2: Z rightarrow Y$, there’s a map $h: Z rightarrow X occasions Y$ that satisfies the commutative diagram in Determine 5.
Whereas this development is slightly concerned for one thing as acquainted as a product it has the exceptional property that it permits us to outline a “product” even when there is no such thing as a underlying set construction (that’s, these settings the place we can’t resort to defining $X occasions Y$ because the set of pairs of $(x,y)$ for $x in X$ and $y in Y$).

Determine 5: The commutative diagram that describes a product $X occasions Y$. For any $Z$ with maps $f_1: Z rightarrow X$ and $f_2: Z rightarrow Y$, there exists a singular map $h: Z rightarrow X occasions Y$ such that $f_1 = pi_1 circ h$ and $f_2 = pi_2 circ h$ the place $pi_1$ and $pi_2$ are the same old projection maps from $X occasions Y$ to $X$ and $X occasions Y$ to $Y$ respectively.
One can moderately argue that diagrammatic descriptions of well-known constructions, like merchandise, usually are not helpful for the machine studying researcher. In any case, we already know how you can kind merchandise in all the areas that come up in machine studying. Then again, there are extra sophisticated examples the place diagrammatics mesh effectively with the way in which we construct neural community architectures in observe.
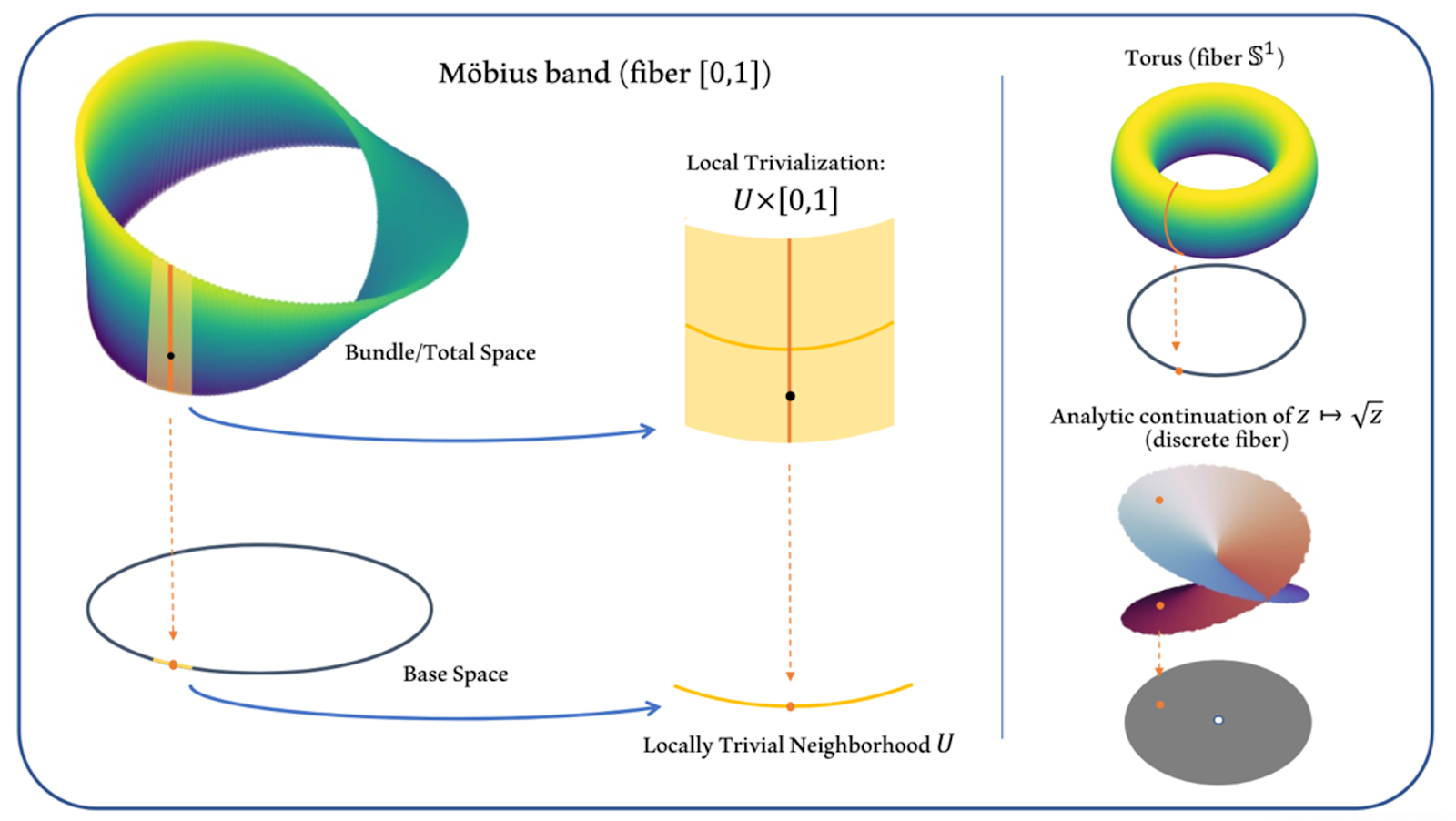
Determine 6: Fiber bundles seize the notion {that a} area may domestically seem like a product however globally have twists in it.
Fiber bundles are a central development in geometry and topology that seize the notion {that a} area might domestically seem like a product however might have twists that break this product construction globally. Evaluate the cylinder with the Möbius band. We will construct each of those by beginning with a circle and taking a product with the road phase $(0,1)$. Within the case of the cylinder, this actually is simply (topologically) the product of the circle and the phase $(0,1)$, however to kind the Möbius band we should add an extra twist that breaks the product construction. In these examples, the circle is named the base area and $(0,1)$ is named the fiber. Whereas solely the cylinder is a real product, each the cylinder and the Möbius band are fiber bundles. Right here is one other mind-set a couple of fiber bundle. A fiber bundle is a union of many copies of the fiber parametrized by the bottom area. Within the Möbius band/cylinder instance, every level on the circle carries its personal copy of $(0,1)$.
We drew inspiration from this latter description of fiber bundles once we had been contemplating a conditional technology process within the context of an issue in supplies science. Because the supplies background is considerably concerned, we’ll illustrate the development by way of a extra pedestrian, animal-classification analogue. Let $M$ be the manifold of all attainable pictures containing a single animal. We will suggest to decompose the variation in components of $M$ into two elements, the species of animal within the picture and all the pieces else, the place the latter may imply variations in background, lighting, pose, picture high quality, and so forth. One may need to discover the distribution of certainly one of these components of variation whereas fixing the opposite. As an example, we’d need to repair the animal species and discover the variation we get in background, pose, and so forth. For instance, evaluating the variation in background for 2 totally different species of insect might inform the entomologist about the popular habitat for several types of beetles.

Determine 7: A cartoon visualizing how the set of all animal pictures may very well be decomposed into an area product of animal species and different forms of variation.
One may hope to resolve this drawback by studying an encoding of $M$ right into a product area $X_1 occasions X_2$ the place $X_1$ is a discrete set of factors comparable to animal species and $X_2$ is an area underlying the distribution of all different attainable forms of variation for a set species of animal. Fixing the species would then quantity to selecting a particular aspect $x_1$ from $X_1$ and sampling from the distribution on $X_2$. The product construction of $X_1 occasions X_2$ permits us to carry out such impartial manipulations of $X_1$ and $X_2$. Then again, merchandise are inflexible buildings that impose robust, world topological assumptions on the actual knowledge distribution. We discovered that even on toy issues, it was onerous to study map from the uncooked knowledge distribution to the product-structured latent area outlined above. On condition that fiber bundles are extra versatile and nonetheless give us the properties we needed from our latent area, we designed a neural community structure to study a fiber bundle construction on an information distribution [48].
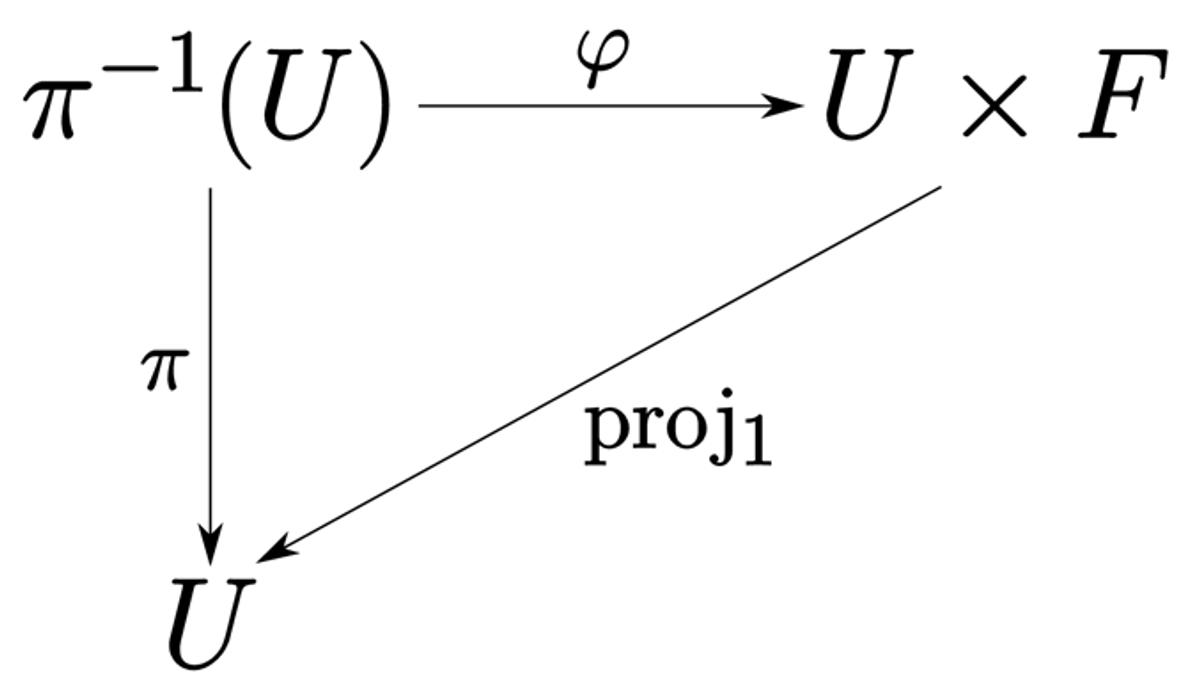
Determine 8: The commutative diagram describing a fiber bundle. The map $pi$ tasks from neighborhoods of the entire area to the bottom area, $U$ is an area neighborhood of the bottom area, and $F$ is the fiber. The diagram says that every level within the base area has a neighborhood $U$ such that once we carry this to the bundle, we get one thing that’s homeomorphic (informally, equal) to the product of the neighborhood and the fiber. However this product construction might not maintain globally over the entire area.
However how can we go from the summary definition of a fiber bundle above to a neural community structure that we will code up on a pc. It seems there’s a succinct diagrammatic definition of a fiber bundle (Determine 8) that may function a handy template to construct up an structure from. We had been capable of proceed in a comparatively naïve trend, taking every of the maps within the diagram and constructing a corresponding stack of layers. The diagram itself then instructed us how you can compose every of those elements collectively. The commutativity of the diagram was engineered by way of a time period within the loss operate that ensures that $pi = textual content{proj}_1 circ varphi$. There have been additionally some situations on $varphi$ and $pi$ (such because the bijectivity of $phi$) that wanted to be engineered. Past this, we had been shocked on the quantity of flexibility we had. That is helpful because it means this course of is basically agnostic to knowledge modality.
That is an elementary instance of how the diagrammatic custom in arithmetic can present us with a broader perspective on the design of neural networks, permitting us to attach deep structural rules with large-scale community design with out having to specify small-scale particulars that may be drawback dependent. In fact, all this fails to attract from something past the floor of what the explicit perspective has to supply. Certainly, class idea holds promise as a unified framework to attach a lot of what seems and is completed in machine studying [49].
Conclusion
Within the mid-twentieth century, Eugene Wigner marveled on the “the unreasonable effectiveness of arithmetic” as a framework for not solely describing present physics but additionally anticipating new leads to the sphere [50]. A mantra extra relevant to latest progress in machine studying is “the unreasonable effectiveness of information” [51] and compute. This might seem like a disappointing state of affairs for mathematicians who might need hoped that machine studying could be as carefully intertwined to superior arithmetic as physics is. Nonetheless, as we’ve demonstrated, whereas arithmetic might not preserve the identical position in machine studying analysis that it has held previously, the success of scale truly opens new paths for arithmetic to assist progress in machine studying analysis. These embrace:
- Offering highly effective instruments for deciphering the interior workings of advanced fashions
- Providing a framework for high-level architectural selections that depart the main points to the educational algorithm
- Bridging historically remoted domains of arithmetic like topology, summary algebra, and geometry with ML and knowledge science purposes.
Ought to the way in which issues have turned out shock us? Maybe not, on condition that machine studying fashions finally replicate the information they’re educated on and most often this knowledge comes from fields (equivalent to pure language or imagery) which have lengthy resisted parsimonious mathematical fashions.
But, this case can also be a chance for arithmetic. Performant machine studying fashions might present a gateway for mathematical evaluation of a spread of fields that had been beforehand inaccessible. It’s exceptional for example that educated phrase embeddings remodel semantic relationships into algebraic operations on vectors in Euclidean area (for example, ‘Italian’ – ‘Italy’ + ‘France’ = ‘French’). Examples like this trace on the potential for arithmetic to realize a foothold in advanced, real-world settings by finding out the machine studying fashions which have educated on knowledge from these settings.
As increasingly of the information on the earth is consumed and mathematicised by machine studying fashions, will probably be an more and more attention-grabbing time to be a mathematician. The problem now lies in adapting our mathematical toolkit to this new panorama, the place empirical breakthroughs typically precede theoretical understanding. By embracing this shift, arithmetic can proceed to play a vital, albeit evolving, position in shaping the way forward for machine studying.
The writer wish to thank Darryl Hannan for assist with figures, Davis Brown, Charles Godfrey, and Scott Mahan for helpful suggestions on drafts, in addition to the employees of the Gradient for helpful conversations and assist enhancing this text. For sources and occasions across the rising neighborhood of mathematicians and laptop scientists utilizing topology, algebra, and geometry (TAG) to raised perceive and construct extra sturdy machine studying techniques, please go to us at https://www.tagds.com.
References
[1] Richard Sutton. “The bitter lesson”. In: Incomplete Concepts (weblog) 13.1 (2019), p. 38.
[2] Guido F Montufar et al. “On the variety of linear areas of deep neural networks”. In: Advances in Neural Data Processing Techniques 27 (2014).
[3] Boris Hanin and David Rolnick. “Complexity of linear areas in deep networks”. In: Worldwide Convention on Machine Studying. PMLR. 2019, pp. 2596–2604.
[4] J Elisenda Grigsby and Kathryn Lindsey. “On transversality of bent hyperplane preparations and the topological expressiveness of ReLU neural networks”. In: SIAM Journal on Utilized Algebra and Geometry 6.2 (2022), pp. 216–242.
[5] Ahmed Imtiaz Humayun et al. “Splinecam: Actual visualization and characterization of deep community geometry and determination boundaries”. In: Proceedings of the IEEE/CVF Convention on Pc Imaginative and prescient and Sample Recognition. 2023, pp. 3789–3798.
[6] Phillip Pope et al. “The intrinsic dimension of pictures and its influence on studying”. In: arXiv preprint arXiv:2104.08894 (2021).
[7] Nicholas Konz and Maciej A Mazurowski. “The Impact of Intrinsic Dataset Properties on Generalization: Unraveling Studying Variations Between Pure and Medical Photos”. In: arXiv preprint arXiv:2401.08865 (2024).
[8] Yasaman Bahri et al. “Explaining neural scaling legal guidelines”. In: arXiv preprint arXiv:2102.06701 (2021).
[9] Utkarsh Sharma and Jared Kaplan. “A neural scaling regulation from the dimension of the information manifold”. In: arXiv preprint arXiv:2004.10802 (2020).
[10] Alessio Ansuini et al. “Intrinsic dimension of information representations in deep neural networks”. In: Advances in Neural Data Processing Techniques 32 (2019).
[11] Lucrezia Valeriani et al. “The geometry of hidden representations of enormous transformer fashions”. In: Advances in Neural Data Processing Techniques 36 (2024).
[12] Henry Kvinge, Davis Brown, and Charles Godfrey. “Exploring the Illustration Manifolds of Steady Diffusion Via the Lens of Intrinsic Dimension”. In: ICLR 2023 Workshop on Mathematical and Empirical Understanding of Basis Fashions.
[13] Xingjun Ma et al. “Characterizing adversarial subspaces utilizing native intrinsic dimensionality”. In: arXiv preprint arXiv:1801.02613 (2018).
[14] Peter Lorenz, Ricard L Durall, and Janis Keuper. “Detecting pictures generated by deep diffusion fashions utilizing their native intrinsic dimensionality”. In: Proceedings of the IEEE/CVF Worldwide Convention on Pc Imaginative and prescient. 2023, pp. 448–459.
[15] Fan Yin, Jayanth Srinivasa, and Kai-Wei Chang. “Characterizing truthfulness in massive language mannequin generations with native intrinsic dimension”. In: arXiv preprint arXiv:2402.18048 (2024).
[16] Justin Gilmer et al. “A loss curvature perspective on coaching instabilities of deep studying fashions”. In: Worldwide Convention on Studying Representations. 2021.
[17] Jeremy Cohen et al. “Gradient descent on neural networks usually happens on the fringe of stability”. In: Worldwide Convention on Studying Representations. 2020.
[18] Seyed-Mohsen Moosavi-Dezfooli et al. “Robustness by way of curvature regularization, and vice versa”. In: Proceedings of the IEEE/CVF Convention on Pc Imaginative and prescient and Sample Recognition. 2019, pp. 9078–9086.
[19] Francisco Acosta et al. “Quantifying extrinsic curvature in neural manifolds”. In: Proceedings of the IEEE/CVF Convention on Pc Imaginative and prescient and Sample Recognition. 2023, pp. 610–619.
[20] Gregory Naitzat, Andrey Zhitnikov, and Lek-Heng Lim. “Topology of deep neural networks”. In: Journal of Machine Studying Analysis 21.184 (2020), pp. 1–40.
[21] Bastian Rieck et al. “Neural persistence: A complexity measure for deep neural networks utilizing algebraic topology”. In: arXiv preprint arXiv:1812.09764 (2018).
[22] Mustafa Hajij, Kyle Istvan, and Ghada Zamzmi. “Cell advanced neural networks”. In: arXiv preprint arXiv:2010.00743 (2020).
[23] Cristian Bodnar. “Topological deep studying: graphs, complexes, sheaves”. PhD thesis. 2023.
[24] Jakob Hansen and Robert Ghrist. “Towards a spectral idea of mobile sheaves”. In: Journal of Utilized and Computational Topology 3.4 (2019), pp. 315–358.
[25] Yifan Feng et al. “Hypergraph neural networks”. In: Proceedings of the AAAI Convention on Synthetic Intelligence. Vol. 33. 01. 2019, pp. 3558–3565.
[26] Felix Draxler et al. “Basically no obstacles in neural community power panorama”. In: Worldwide Convention on Machine Studying. PMLR. 2018, pp. 1309–1318.
[27] Kiho Park, Yo Joong Choe, and Victor Veitch. “The linear illustration speculation and the geometry of enormous language fashions”. In: arXiv preprint arXiv:2311.03658 (2023).
[28] Taco Cohen and Max Welling. “Group equivariant convolutional networks”. In: Worldwide Convention on Machine Studying. PMLR. 2016, pp. 2990–2999.
[29] Maurice Weiler, Fred A Hamprecht, and Martin Storath. “Studying steerable filters for rotation equivariant cnns”. In: Proceedings of the IEEE Convention on Pc Imaginative and prescient and Sample Recognition. 2018, pp. 849–858.
[30] Daniel E Worrall et al. “Harmonic networks: Deep translation and rotation equivariance”. In: Proceedings of the IEEE Convention on Pc Imaginative and prescient and Sample Recognition. 2017, pp. 5028–5037.
[31] Diego Marcos et al. “Rotation equivariant vector discipline networks”. In: Proceedings of the IEEE Worldwide Convention on Pc Imaginative and prescient. 2017, pp. 5048–5057.
[32] Alexandre Duval et al. “A Hitchhiker’s Information to Geometric GNNs for 3D Atomic Techniques”. In: arXiv preprint arXiv:2312.07511 (2023).
[33] Nathaniel Thomas et al. “Tensor discipline networks: Rotation-and translation-equivariant neural networks for 3d level clouds”. In: arXiv preprint arXiv:1802.08219 (2018).
[34] Manzil Zaheer et al. “Deep units”. In: Advances in Neural Data Processing Techniques 30 (2017).
[35] Vıctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. “E (n) equivariant graph neural networks”. In: Worldwide Convention on Machine Studying. PMLR. 2021, pp. 9323–9332.
[36] Denis Boyda et al. “Sampling utilizing SU (N) gauge equivariant flows”. In: Bodily Assessment D 103.7 (2021), p. 074504.
[37] Hannah Lawrence and Mitchell Tong Harris. “Studying Polynomial Issues with SL(2,mathbb {R}) −Equivariance”. In: The Twelfth Worldwide Convention on Studying Representations. 2023.
[38] Josh Abramson et al. “Correct construction prediction of biomolecular interactions with AlphaFold 3”. In: Nature (2024), pp. 1–3.
[39] Scott Mahan et al. “What Makes a Machine Studying Activity a Good Candidate for an Equivariant Community?” In: ICML 2024 Workshop on Geometry-grounded Illustration Studying and Generative Modeling.
[40] Johann Brehmer et al. “Does equivariance matter at scale?” In: arXiv preprint arXiv:2410.23179 (2024).
[41] Chris Olah et al. “Naturally Occurring Equivariance in Neural Networks”. In: Distill (2020). https://distill.pub/2020/circuits/equivariance. doi: 10.23915/distill.00024.004.
[42] Giovanni Luca Marchetti et al. “Harmonics of Studying: Common Fourier Options Emerge in Invariant Networks”. In: arXiv preprint arXiv:2312.08550 (2023).
[43] Rahim Entezari et al. “The position of permutation invariance in linear mode connectivity of neural networks”. In: arXiv preprint arXiv:2110.06296 (2021).
[44] Samuel Ok Ainsworth, Jonathan Hayase, and Siddhartha Srinivasa. “Git re-basin: Merging fashions modulo permutation symmetries”. In: arXiv preprint arXiv:2209.04836 (2022).
[45] Bo Zhao et al. “Symmetry teleportation for accelerated optimization”. In: Advances in Neural Data Processing Techniques 35 (2022), pp. 16679–16690.
[46] Bo Zhao et al. “Enhancing Convergence and Generalization Utilizing Parameter Symmetries”. In: arXiv preprint arXiv:2305.13404 (2023).
[47] Charles Godfrey et al. “On the symmetries of deep studying fashions and their inside representations”. In: Advances in Neural Data Processing Techniques 35 (2022), pp. 11893–11905.
[48] Nico Courts and Henry Kvinge. “Bundle Networks: Fiber Bundles, Native Trivializations, and a Generative Strategy to Exploring Many-to-one Maps”. In: Worldwide Convention on Studying Representations. 2021.
[49] Bruno Gavranović et al. “Place: Categorical Deep Studying is an Algebraic Concept of All Architectures”. In: Forty-first Worldwide Convention on Machine Studying.
[50] Eugene P Wigner. “The unreasonable effectiveness of arithmetic within the pure sciences”. In: Arithmetic and Science. World Scientific, 1990, pp. 291–306.
[51] Alon Halevy, Peter Norvig, and Fernando Pereira. “The unreasonable effectiveness of information”. In: IEEE Clever Techniques 24.2 (2009), pp. 8–12.
[ad_2]
{kind=link}